<머신러닝>
- 주로 3가지 분야로 나누어진다.
1. 지도하습 : 데이터를 예측하거나 분류를 수행
2. 비지도학습 : 축적된 데이터의 구조나 관계성을 찾아내는것
3. 강화학습 : 보수나 환경등을 설정하여 수익을 최대화하는 행동을 학습하는 방법
1-1. 회귀 : 기존 데이터에서 관계성을 바탕으로 데이터 예측, 주가나 시가와 같은 연속적인 값 예측
1-2. 분류 : 데이터 예측 실시. 예측되는 값은 데이터의 카테고리, 이산값.
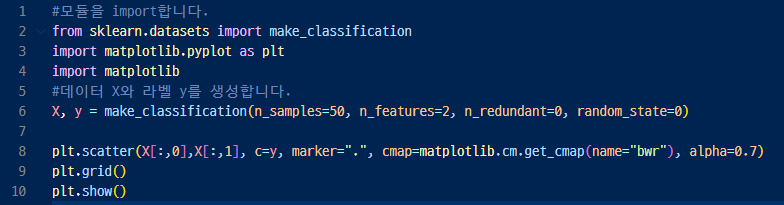
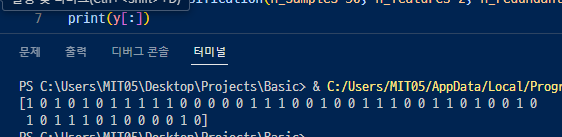
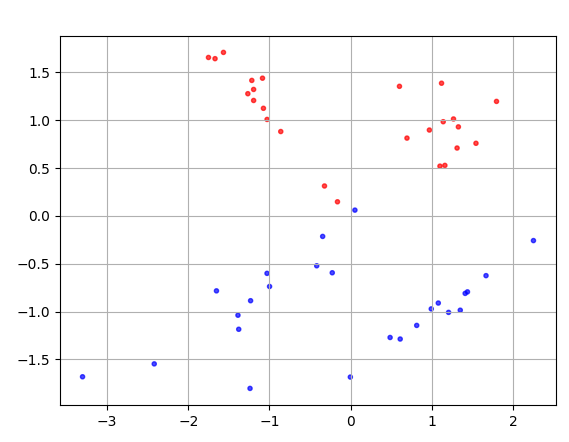
8행 - X값의 첫번째 열 값, X값의 두번째 열 값 으로 그래프 그림. y를 출력해보면 이렇게 0과 1로 이항분류가 되어있음.
<학습과 예측>
- 모델 model : 머신러닝의 학습 방법
- 분류기 classifier : 머신러닝으로 데이터를 분류하는 프로그램
>> 모델을 직접 구현하는 것은 쉽지 않음. 그래서 파이썬에 있는 머신러닝에 특화된 라이브러리를 사용
▷ 그중에 대표적인게 scikit-learn.
▼ 가상모델 Classifier의 사용법
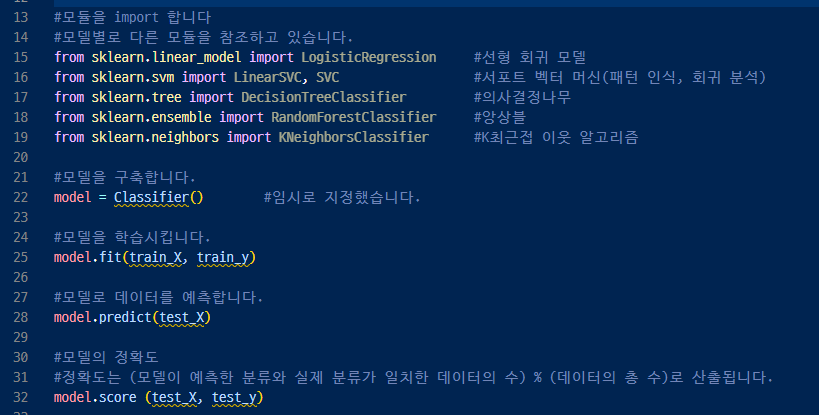
▼ 선형회귀모델을 사용해서 데이터 예측과 예측 결과를 출력하기.
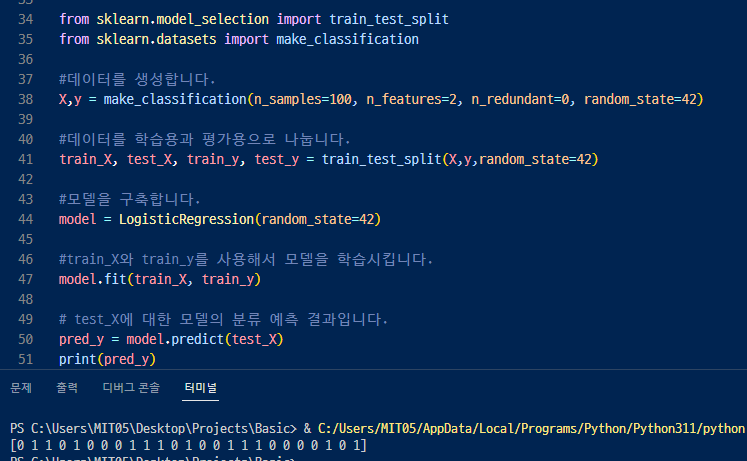
38행 > make_classification, 가상의 데이터를 만듬. n_features 만큼 나눠서 (이러면 X값이 이 수만큼 열이 나옴)
41행 > https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.train_test_split.html
▶ 25%가 test_size 기본 값.
fit() > 모델을 학습시키는, 그래서 x값과 y값(라벨, 정답,타겟)을 넣어서 학습시키고
predict() > 으로 X값을 넣어서 y 값 예측 결과를 도출할 수 있다.
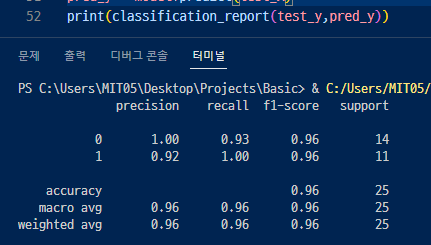
▼ 저번시간에 배운 평가지표를 출력할 수 있는 classification_report 함수를 이용하면 이렇게 나온다
'머신러닝 > 개념익히기' 카테고리의 다른 글
| 기본 선형 SVM (0) | 2023.07.18 |
|---|---|
| 로지스틱 회귀 (0) | 2023.07.18 |
| 머신러닝의 기본적인 흐름 및 평가 지표 함수 (0) | 2023.07.17 |
| 혼동행렬 / 성능평가지표 (0) | 2023.07.17 |
| 학습/테스트데이터 - 홀드아웃, k-분할 교차검증, 과적합, 앙상블학습 (0) | 2023.07.17 |



