머신러닝은 훈련데이터/테스트 데이터를 준비한 후 머신러닝 알고리즘을 훈련 데이터로 학습시키고
학습된 머신러닝 알고리즘의 성능을 테스트 데이터로 검증하는 흐름을 가지고 있음.

81행, svm.SVC > SVM(Support Vector Machine)은 데이터 분석 중 분류에 해당되며 지도학습 방식의 모델임.
sklearn을 통해서 구현 가능함. 자세히 여기 ▼ 자세한 내용은 추후에 공부해서 추가하기
https://scikit-learn.org/stable/modules/generated/sklearn.svm.SVC.html
85행, predict(알고싶은 데이터) : 예측해서 머신러닝 학습 결과를 알 수 있음.
> 그렇게 86행에서 예측한 학습결과의 정확률 accuarcy_score 메서드를 이용해서 파악할 수 있음.
▶ 여기서는 0.60으로 낮은 값이 나왔는데 데이터를 전처리하지 않고 그대로 써서 낮은 정확도가 되어버림.
▷ 그래서 데이터 전처리(data pre-processing)이 중요하다.
<성능평가지표 알아보는 함수>
- 성능 평가 지표는 : https://dev-adela.tistory.com/162
● accuarcy_score() : 정확도 (정답률) - 실제 데이터 중 맞게 예측한 데이터의 비율
● presicion_score() : 적합율(Positive Predicitive value, PPV)
- positive에 속한다고 출력한 샘플 중 실제로 positive에 속하는 샘플 수의 비율
- FP가 커지면 적합율을 작아진다.
● recall_score() :재현율 - 실제 데이터 중 positive 클래스에 속한다고 출력한 표본의 수의 비율,
- (실제 양성 데이터 중 양성으로 예측된 것의 비율)
- FN이 커지면 재현율이 작아진다.
● fl_score : f1 측정 값
● https://scikit-learn.org/stable/modules/generated/sklearn.metrics.classification_report.html

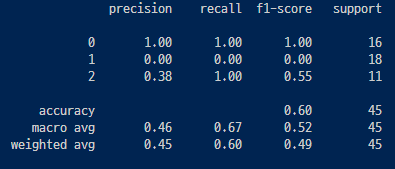
classification_report() : 분류 모델의 평가 지표를 출력해주는 함수, 정확도(Accuracy), 정밀도(Precision), 재현율(Recall), F1-score 등의 평가지표를 쉽게 확인할 수 있음. (Support는 클래스의 실제 데이터 수)
*** fit과 predict 관련해서도 알아봐야지 ***
'머신러닝 > 개념익히기' 카테고리의 다른 글
| 로지스틱 회귀 (0) | 2023.07.18 |
|---|---|
| 머신러닝 기초, 지도학습(분류) (0) | 2023.07.18 |
| 혼동행렬 / 성능평가지표 (0) | 2023.07.17 |
| 학습/테스트데이터 - 홀드아웃, k-분할 교차검증, 과적합, 앙상블학습 (0) | 2023.07.17 |
| 지수함수와 로그함수 (0) | 2023.05.16 |



