<기본 선형 SVM의 예>
- 로지스틱 회귀처럼 데이터의 경계선을 찾아내 데이터를 분류하지만
가장 큰 특징은 서포트 벡터가 있다는 점.
> 가장 가까이 있는 데이터와 경계선의 거리를 가리킴. 거리 합을 최대화함으로써 경계선을 결정하는 방법.
가장 먼곳에 분류할 경게선이 그려지기 때문에 로지스틱 회귀에 비해 일반화하기 쉬움. > 예측이 향상됨.
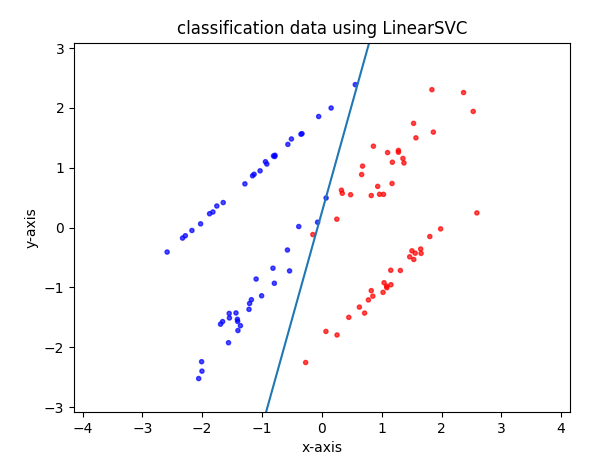
▲ 일반 선형 SVM은 이렇게 흘러간다. 그렇게 흘러가서 짠게 요고 ▼
선형과 비선형의 모델의 정확도를 출력하면 이렇게 ▼ 비선형이 훨씬 훨씬 높다.
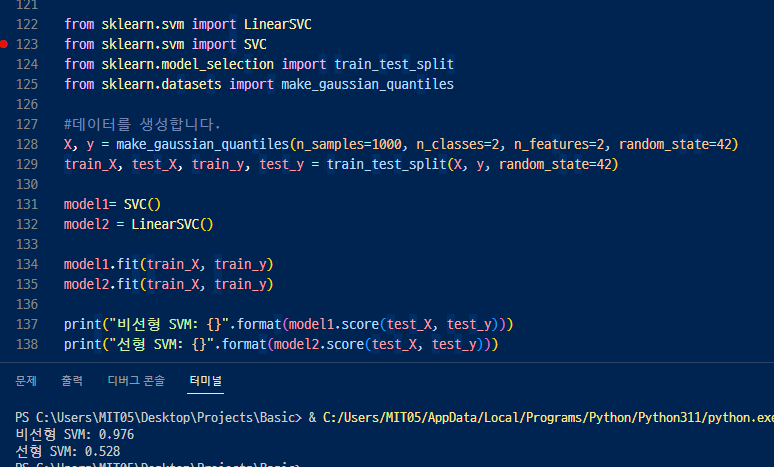
sklearn.datasets.make_gaussian_quantiles
Examples using sklearn.datasets.make_gaussian_quantiles: Plot randomly generated classification dataset Multi-class AdaBoosted Decision Trees Two-class AdaBoost
scikit-learn.org
'머신러닝 > 개념익히기' 카테고리의 다른 글
| 머신러닝 랜덤포레스트 / k-NN (0) | 2023.07.19 |
|---|---|
| 결정트리, decision tree (0) | 2023.07.18 |
| 로지스틱 회귀 (0) | 2023.07.18 |
| 머신러닝 기초, 지도학습(분류) (0) | 2023.07.18 |
| 머신러닝의 기본적인 흐름 및 평가 지표 함수 (0) | 2023.07.17 |



