결정 트리는 규칙 생성 로직을 제어하지 않으면 완벽하게 분류하기 위해
트리 노드를 계속해서 만들어 감.
그래서 나중에는 매우 복잡한 규칙 트리가 생길 수 있음.
▶ 이는 쉽게 과적합, Overfitting이 될 수 있다는 것을 의미함.
▷ 그래서 결정 트리는 과적합이 상당히 높은 ML 알고리즘 중 하나임
이를 제어하기 위해 max_depth, min_samples_leaf 등 하이퍼파라미터를 튜닝하는 것임
<결정 트리 과적합, Overfitting>
- 어떻게 학습 데이터를 분할해서 예측을 수행하는지, 이로 인한 과적합 문제를 시각화 해볼 예정
▶ 분류를 위한 데이터 세트를 임의로 만들어 봄
▷ 사이킷런에서 분류 테스트용 데이터를 쉽게 만들 수 있도록 make_classification() 함수 제공
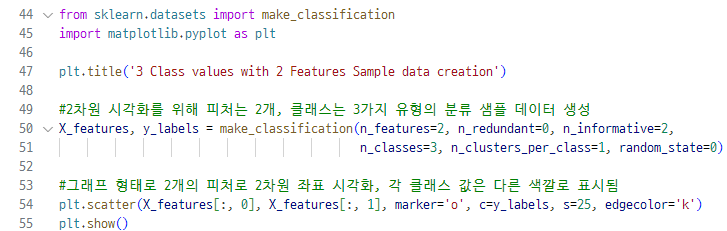

▷ 각 피처 X, Y축으로 나열된 2차원 그래프임. 3개의 클래스 값 구분은 색깔로 되어있음
▶ 이제 X_features와 y_labels 데이터 세트 기반으로 결정 트리 학습
- 처음이니까 하이퍼 파라미터를 디폴트로 두고 함

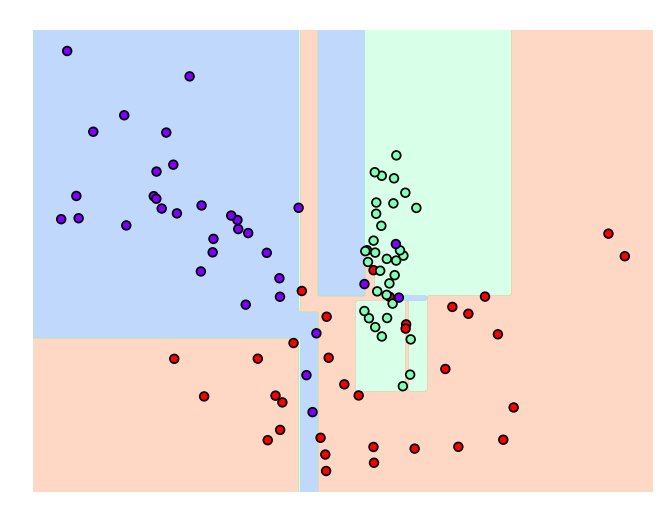
▲ 모델이 어떤 결정 기준을 가지고 분할하면서 데이터를 분류하는지 확인.
중간중간 껴있는 친구들이 이상치(Outlier) 데이터인데,
그래프를 보면 알 수 있듯이 얘네 때문에 결정 기준 경계가 많아짐.
이런 복잡하게 된 모델은 학습 데이터와 약간만 다른 데이터 세트를 예측하면
예측 정확도가 떨어지게 됨.
▶ 이번에는 min_samples_leaf = 6으로 설정해서 해봄.
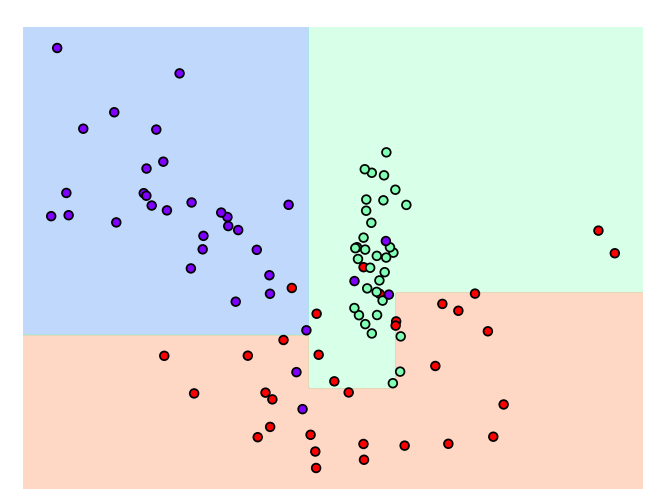
보면 이상치가 있음에도 불구하고 이에 대한 영향을 받지 않으면서
일반화된 분류 규칙에 따라 분류되었음.
▶ 이러면 min_samples_leaf=6인 모델의 성능이 더 좋을 가능성이 높음.
▷ 왜냐하면 학습 데이터에만 지나치게 최적화되면 다른 데이터에서는 정확도가 떨어질 수 있기 때문에
= 이를 과적합, Overfitting 이라고 함.
'머신러닝 > 개념익히기' 카테고리의 다른 글
| ML XGBoost(eXtra Gradient Boost) w.위스콘신 유방암 데이터 (0) | 2023.12.21 |
|---|---|
| ML AdaBoost, GBM(Gradient Boosting Machine) (5) | 2023.12.20 |
| ML feature의 중요한 역할 지표 (결정 트리 알고리즘) (2) | 2023.11.28 |
| ML 결정 트리 모델 시각화 Graphviz (2) | 2023.11.28 |
| ML 데이터 전처리, Data preprocessing 정의 (0) | 2023.11.26 |



