<부스팅>
- weak learner (약한 학습기) 여러개를 순차적으로 학습-예측 하면서
잘못 예측한 데이터에 가중치를 부여해 오류를 개선하며 학습하는 방식
- 주로 AdaBoost(Adaptive boosting), Gradient Boost가 있음.
<에이다 부스트 AdaBoost>
- 오류 데이터에 가중치를 부여하며 부스팅을 수행하는 대표적인 알고리즘
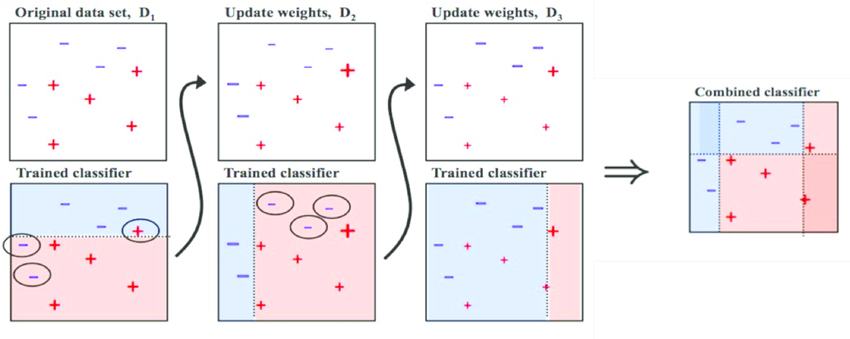
- D1, 피치 데이터 세트에서
- 분류기준(weak learner, 약한 학습기)으로 (파란색 부분) +와 - 를 분류했을 때,
잘못 분류된 오류 데이터(동그라미 쳐진 부분)이 발생된다.
- 그래서 이 오류데이터에 가중치 값을 부여한다(그림상으로는 조금 더 커짐)
이러한 부분들을 N번 반복하고,
▶ 약한 학습기가 순차적으로 유 값에 대해 가중치를 부여한 예측 결정 기준을 모두 결합해서 예측을 수행한다.
▷ 이것이 에이다 부스트, Adaboost
<GBM(Gradient Bosst Machine)>
이것도 위에서 설명한 AdaBoost와 유사하지만,
GBM은 가중치 업데이트를 경사 하강법(Gradient Descent)으로 하는 것이 가장 큰 차이.
- 오류 값 : 실제 값 - 예측값
- 경사하강법(Gradient Descent) : 오류값 을 최소화하는 방향성을 가지고 반복적으로 가중치 값 업데이트 하는 것
- CART(Classification and Regression Trees) 기반의 알고리즘. = 분류도 되고 회귀도 되고
▼ 랜덤포레스트에서 했던것 처럼(https://dev-adela.tistory.com/266) iris를 사용해 GBM 시간 재보기
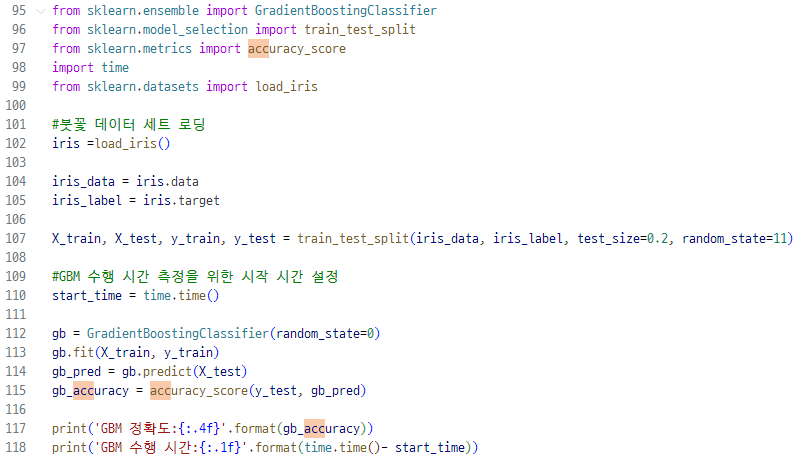

여전히 정확도는 93%나오는데 아마 데이터 수가 적어서 그런게 아닐까 ㅎ
<GBM 하이퍼 파라미터>
- loss : 경사하강법에서 사용할 비용함수 지정. 기본값은 deviance
- learning_rate : 학습 진행할 때마다 적용하는 학습률.
Weak learner가 순차적으로 오류 값을 보정해 나가는데 적용하는 계수.
너무 크면 오류값 찾지 못하고 그냥 지나치고(성능 떨어짐), 너무 적으면 시간이 오래걸림.
- n_estimators : weak learner의 개수. 개수가 많을 수록 예측 성능이 일정 수준까지는 좋아짐
▶ learning_rate랑 n_estimators랑 상호 보완적으로 조합해서 사용함. l_r은 작게, n_estimators는 크게(이런식으로)
- subsample : weak learner가 학습에 사용하는 데이터 샘플링 비율. 기본값은 1(전체 학습 데이터를 기반으로 학습한다).
'머신러닝 > 개념익히기' 카테고리의 다른 글
| ML LightGBM w.위스콘신 유방암 데이터 (4) | 2024.01.02 |
|---|---|
| ML XGBoost(eXtra Gradient Boost) w.위스콘신 유방암 데이터 (0) | 2023.12.21 |
| ML 결정 트리 과적합 Overfitting (2) | 2023.11.29 |
| ML feature의 중요한 역할 지표 (결정 트리 알고리즘) (2) | 2023.11.28 |
| ML 결정 트리 모델 시각화 Graphviz (2) | 2023.11.28 |



