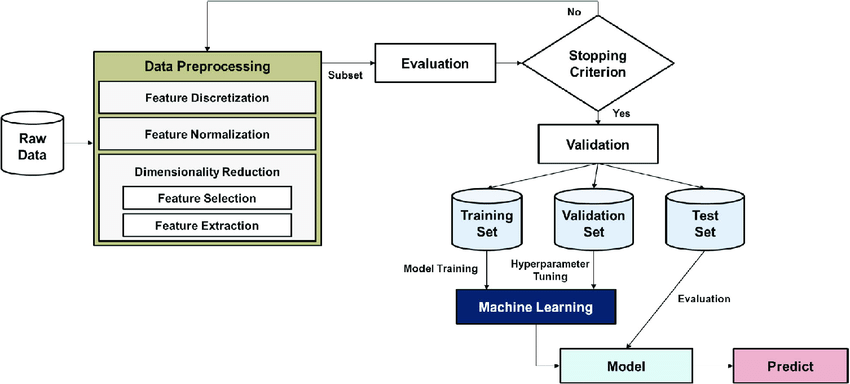
머신러닝을 학습하기에 앞서 매우 중요한 작업이 하나 있는데
바로 데이터 전처리, Data preprocessing 이다.
▶ 데이터를 사전 처리하고 가공해서 준비하는 과정이다.
이걸 해야지 데이터의 품질을 향상시키고 학습할 수 있도록 도움을 주고
성능이 좋아지고 효율이 좋아지고 등등,,
1. 데이터 클리닝 (Data Cleaning)
- 결측치 처리, 이상치 처리, 중복된 데이터 처리, 잘못된 데이터나 이상한 값들을 수정
이러한 작업들이 여기에 해당된다. 이러한 작업을 통해 데이터의 품질을 향상시키는 것이 목적
pandas의 isnull이나 boxplot을 활용해서 확인한 이상치나 결측치 처리들이 여기에 해당된다.
2. 피처 스케일링 (Feature Scaling)
- 피쳐들의 범위를 일치시키는 작업.
주로 표준화, 그리고 정규화가 여기에 해당된다.
데이터의 분포가 균일하지 않을 때하는 작업들이다.
3. 범주형 데이터 인코딩 (Categorical Data Encoding)
- 범주형 변수를 숫자 형태로 변환하는 작업.
원-핫 인코딩과 레이블 인코딩이 여기에 해당된다.
학습할 때 문자열을 하지 않기 때문에..!
4. 피쳐 엔지니어링 (Feature Engineering)
- 새로운 피처를 생성하거나 (기존의 피처들 조합하거나 변형해서)
피쳐들을 조합해서 다항 특성을 추가하거나 시계열 데이터에서 시간 특성을 추출하는 것을 뜻함.
모델의 성능을 향상시키기 위해서 하는 피처들을 변형하고 생성하는 작업들.
5. 차원 축소 (Dimensionality Reduction)
- 피처의 수를 줄이기 위해 대표적인 주성분 분석(PCA) 등의 기법을 사용해 차원 축소
차원이 커질수록 데이터의 수도 늘어나게 되고.. 차원이 무작정 커지게 되면 차원의 저주가 생김.
만약 데이터 수는 적은데 차원만 많아지면 전체 공간에서 데이터가 차지하는 비중이 희박해진다.
그럼 유의미한 패턴 파악이 어렵게 된다. ▶ 이러한 원인 그리고 성능 저하라는 결과가 생김.
그래서 가지고 있는 정보를 최대한 보존하면서 차원을 줄이는 기법.
주로 비지도 학습에서 사용됨 (물론 분류나 회귀, 시각화 할때도 사용되긴 함)
6. 데이터분할 (Splitting Data)
- 훈련용, 검증용, 테스트용으로 나누어 모델의 훈련 및 평가에 사용하는 것.
우리가 엄청 많이 한, train_test_split ()
모든 데이터들이 위의 모든 단계를 하지는 않고.
데이터에 따라 생략하는 단계도 있다.
'머신러닝 > 개념익히기' 카테고리의 다른 글
| ML feature의 중요한 역할 지표 (결정 트리 알고리즘) (2) | 2023.11.28 |
|---|---|
| ML 결정 트리 모델 시각화 Graphviz (2) | 2023.11.28 |
| ML XGBoost 하이퍼파라미터 조정 (0) | 2023.11.19 |
| ML 앙상블 Ensemble- 랜덤포레스트, RandomForest (0) | 2023.11.02 |
| ML F1 score, ROC 곡선과 AUC (0) | 2023.10.23 |



