<데이터모델링>
자세한 내용은 여기 https://dev-adela.tistory.com/144
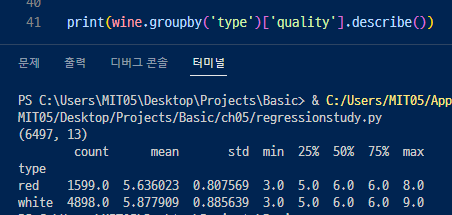
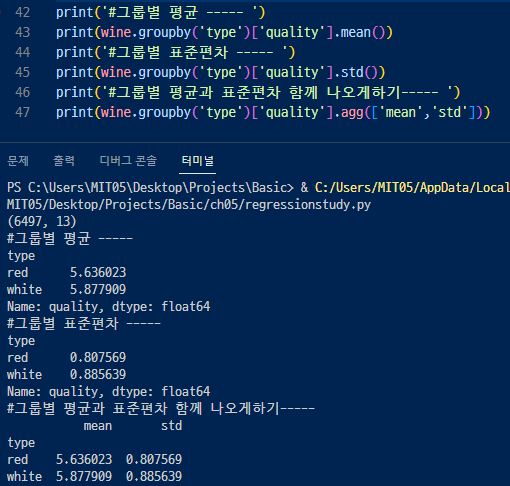
<t-검정, ttest> - install statsmodels 설치 필요.
- 일반적으로 두개의 그룹을 비교해봄.
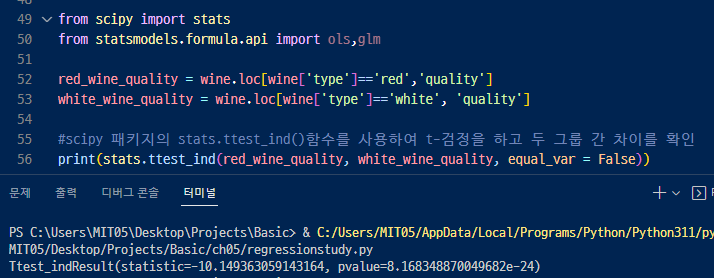

pvalue 값을 가지고 판단하게 됨. 작으면 작을수록 차이가 적다.
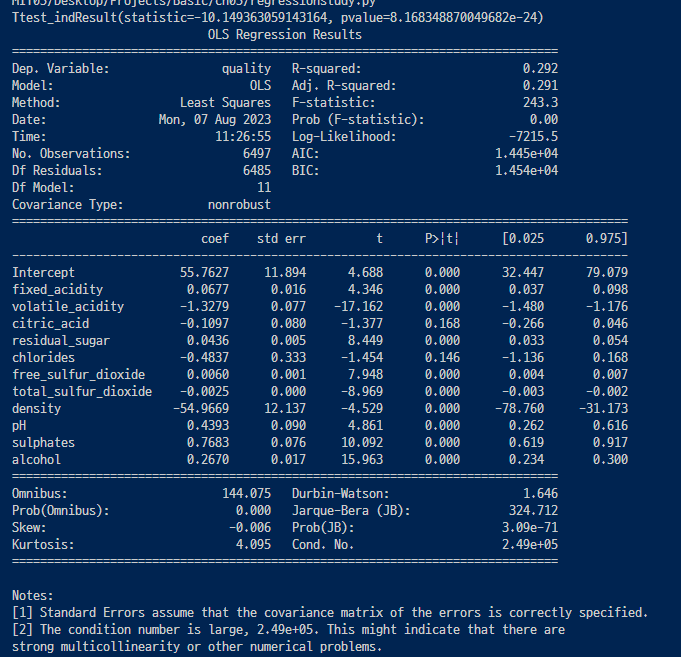
회귀분석할때는 변수를 다 적어줘야함.(p값과 t값이 같이 나옴.)
귀무가설 정의 ▷ 표본추출 ▷ 통계 기법을 통한 검정 ▷ 귀무가설 기각/채택
2개면 t-test로 많이하고 3개이상이면 anova
▶ 자세히 : https://sysiphe0.tistory.com/5
< 새로운 값을 넣으면 이쪽인지 저쪽인지 알 수 있게! 품질 등급 예측하기>
- 기존에 있는 값에서 일부 떼어내서 예측해보기
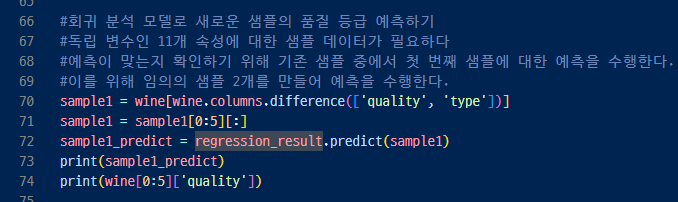

- 새로운 데이터를 만들어서(딕셔너리 형태로) 예측해보기
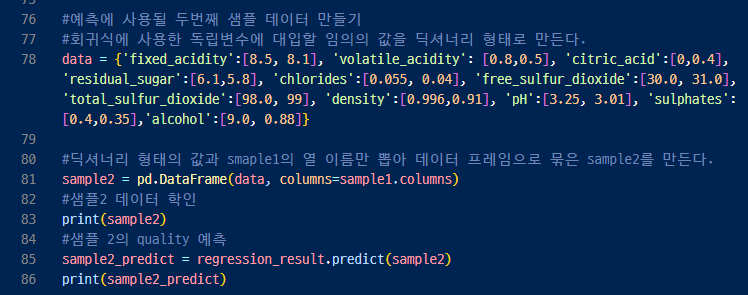
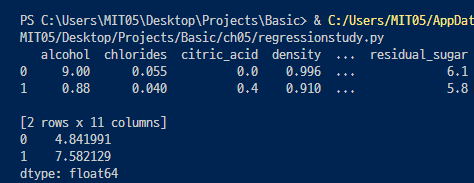
>> 이를 그래프로 그려보기


▶ 선들이 확률밀도 함수값(y축),
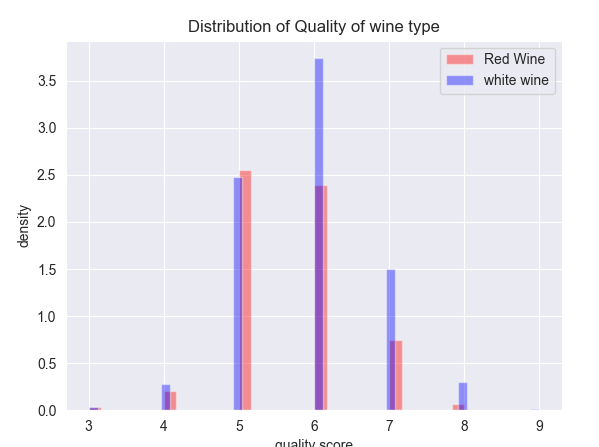
▶ 분석결과를 시각화한것인데. 와인유형에 따른 품질 등급을 히스토그램으로 나타냄.
▼ 부분 회귀 플롯으로 시각화
- 독립 변수가 2개 이상인 경우에는 부분 회귀 플롯 partrial regression plot을 사용해서
하나의 독립 변수가 종속 변수에 미치는 영향력을 시각화함으로써 결과를 분석할 수 있다.
- fixed_acidity가 종속변수 quality에 미치는 영향을 분석하기 위해 부분 회귀 결과를 시각화 해보고
각 독립 변수에 대한 부분 회귀 결과를 시각해봄.

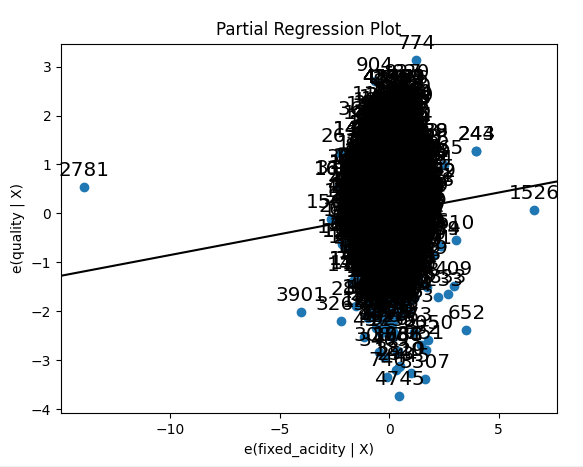
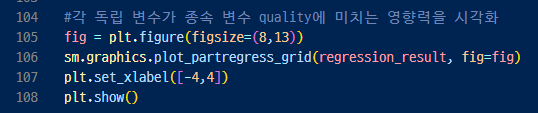

https://www.statsmodels.org/stable/graphics.html
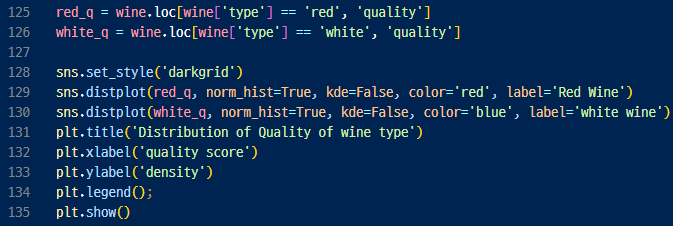
- 와인 종류별 품질의 분포 그래프로 그리기
<상관관계>
상관분석에대해 좀더 공부해야할듯 ㅠ_^

corr 은 상관계수를 가지고 있음.
값이 대각선으로 1.00 으로 나옴. >> 뭔소리야 유튭다시봐
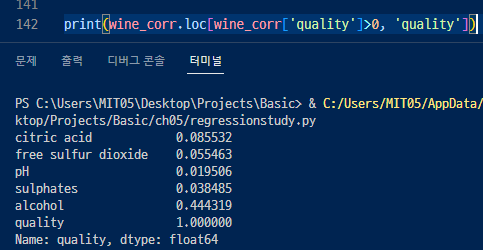
퀄리티와 관련된 부분에서 상관수가 0보다 큰 것을 추출.
양의 상관관계를 가지는 변수들.
퀄리티에서 알콜과의 관계가 가장 큰 변수다. ( 퀄리티에서 가장 가까운 수이기때문에)
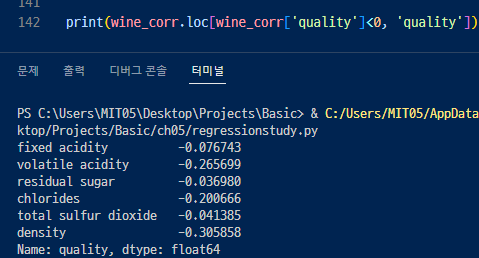
음의 상관관계를 가지는 변수들.
절대값이 0보다 큰 변수들이 관계가 가장 큰 변수다.


kind에 regression을 지정하면 회귀선과 관련된 부분을 표시해서 전체적인 경향성 파악 가능
히스토그램 > 알코올 도수의 평균과 표준편차는 두 그룹이 비슷함. 잔여당의 평균과 표준편차는 화이트와인이 더 큼.
회귀선 > 알코올 도수가 증가하면 품질이 높아짐. 잔여당이 증가하면 품질이 낮아짐.
알코올 도수는 양의 상관관계, 잔여당은 음의 상관관계 (회귀선을 통해 확인 가능)
'머신러닝 > 프로젝트' 카테고리의 다른 글
| Proj 보스턴 주택 가격 회귀분석 (0) | 2023.08.09 |
|---|---|
| Proj 타이타닉호 생존율 분석, 상관관계 찾기 (0) | 2023.08.08 |
| Proj Wine 속성을 이용한 포도 품종 예측 (0) | 2023.08.07 |
| Proj 데이터 기술통계분석 / 데이터 탐색 - 와인 퀄리티 (2) (0) | 2023.08.07 |
| Proj 데이터 기술통계 분석/ 개요, 데이터 준비 - 와인 퀄리티 (1) (0) | 2023.08.07 |



