<Aggregation 함수>
- DataFrame에서 aggregation 함수 적용은 RDBMS에서의 aggregation 함수 적용과 유사함.
▶ count() , 개수를 세어주는데, Null(NaN)값을 반영하지 않은 결과를 반환한다.

▶ min() , max(), sum(), mean()과 같은 aggregation 함수를 적용하기 위해서 컬럼들을 추출해 적용하면 된다.

<groupby( )>
-햐 RDBMS에서도 중요한 groupby.
- 사용시 파라미터 by에 컬럼을 입력하면 대상 컬럼으로 groupby된다.
▷ 그 후 groupby( )를 호출하면 DataFrameGroupBy라는 형태의 데이터 프레임이 반환된다.
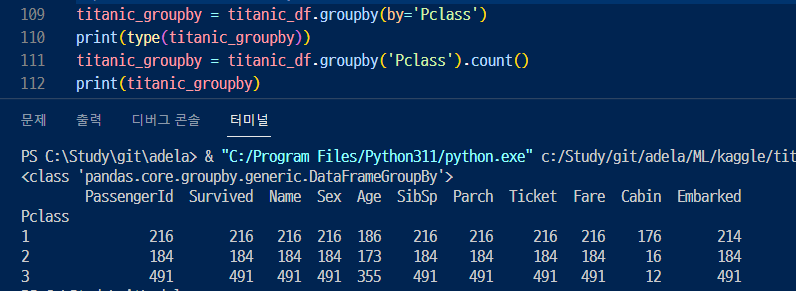
▶ DataFrame에서는 groupby()를 호출해 반환된 결과에 aggregation 함수를 쓸 수 있다!

▶ groupby해서 'Pclass'를 묶고, PassengerId와 Survived의 컬럼 값만 count 했다.
▶여러 개의 aggregation 함수를 쓰고 싶다면 DataFrameGroupBy 객체에서 agg ( ) 메서드를 사용하면 된다..? 와우 어메이징

agg ( ) 메서드 자세한 내용 ▼
아니 람다도 혼합해서 쓴다고...?어메이징...
▷ 만약 서로 다른 여러 개의 컬럼을 서로 다른 aggregation 함수를 쓰고 싶다면...? (좀 복잡함)

▶ 딕셔너리 형태로 aggregation이 적용된 컬럼과 함수를 입력하면 됨.
'데이터분석 > Pandas&Numpy' 카테고리의 다른 글
| pandas apply와 lambda 만남으로 데이터 가공 (0) | 2023.07.07 |
|---|---|
| pandas 결손 데이터를 처리하는 isna, fillna (0) | 2023.07.07 |
| pandas DataFrame과 Series의 정렬 (0) | 2023.07.06 |
| pandas iloc, loc, boolean Indexing/Slicing (0) | 2023.07.06 |
| Kaggle - Titanic 데이터로 연습하는 Pandas 01 (0) | 2023.07.05 |



