이 데이터로 머신러닝 해보려고합니다.......

요런식의 csv파일도 아니고 뭐지 하고 열어봤더니
- index나 wine.names는 데이터 설명서이고 사용할 파일은 wine.data
<개요>
| 포도 품종 예측하기 | |
| 목표 | 와인의 속성을 분석해서 포도 품종을 예측한다. |
| 핵심 개념 | 기술 통계, 의사결정트리, K-Fold cross validation, 성능확인, 산점도 그래프 |
| 데이터 수집 | UCI Machine Learning Repository 에서 다운로드 |
| 데이터 내용 | 독립 변수 12개(('Alcohol','Malic acid','Ash', 'Alcalinity of ash ', 'Magnesium', 'Total phenols', 'Flavanoids','Nonflavanoid phenols','Proanthocyanins','Color intensity','Hue', 'OD280/OD315 of diluted wines','Proline') 종속 변수 1개 ('Class') |
| 데이터 준비 | 수집한 데이터 columns 명과 데이터 값 일치 |
| 데이터 탐색 | 정보 확인 : info() 기술 통계 확인 : info(), describe(), unique(), value_counts() |
| 데이터 모델링 | 1. 학습/예측 및 검증 - 훈련 데이터 및 테스트 데이터 나누기 : train_test_split() - 학습, 의사결정 트리 : DecisionTreeClassifier # 해당 학습 선정 이유 : 전체 자료를 몇 개의 집단으로 분류하거나 예측을 수행하는 분석 방법이기 때문에 - 학습 : fit() 2. 품질 등급 예측 및 검증 - 샘플을 독립변수(x)로 지정→ 의사결정트리 모델 적용 → 종속 변수(y) 예측 - 검증 : K-Fold Cross Validation (6회) 3. 시각화 - 상관관계가 가장 높은 독립변수(속성)과 Class와의 산점도 그래프를 통해 분류 확인 |
- 사용된 모듈

<데이터 준비>
원래 데이터는 이렇게 준비되어있음 (컬럼값이 없었음)
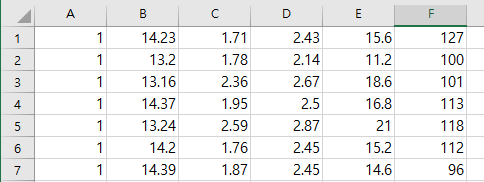
▼ 그래서 컬럼값을 주고 데이터를 불러와서 새로 저장


▶ 그리고 컬럼명에 공백에 _으로 바꿔주고
<데이터 탐색>
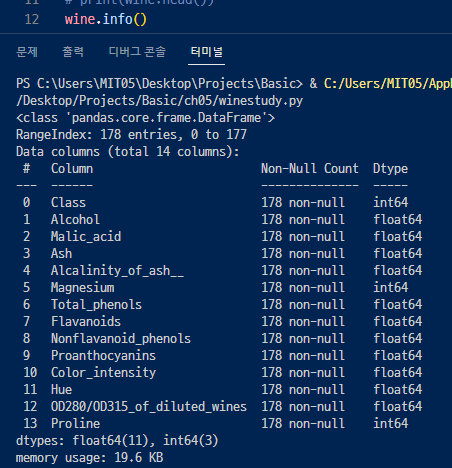
▲ info() 를 통해 정보를 확인한다. 총 14개의 컬럼, 178개의 행(데이터셋), 그리고 각각의 데이터타입까지
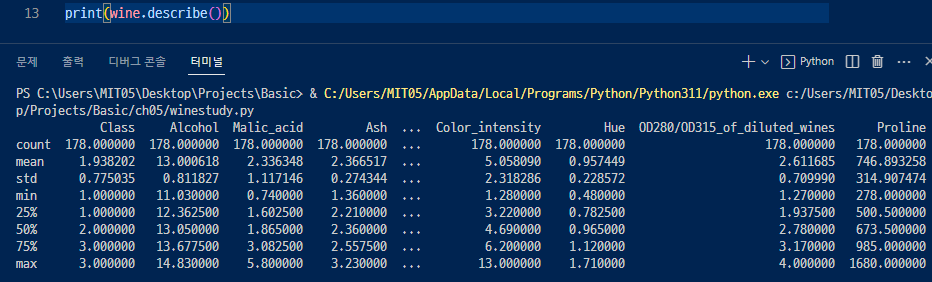
▲ 그리고 describe()를 통해 데이터 정보들을 본다.
Class를 살펴보면 min은 1 max 3인거 보면 1~3의 값밖에 없어보이므로 탈락(사실은 종속변수)
그래서 .unique() 메서드를 써서 더블 체크를 해보자면

역시나 1,2,3밖에 없는 것을 확인할 수 있다. 3가지 종류로 분류 되어있다.
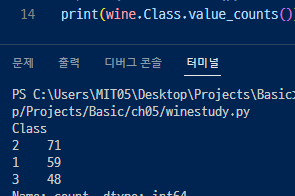
▶ 갯수를 세어보면(.value_counts()메서드) 2가 71개로 제일 많고 3이 48개로 제일 적다.
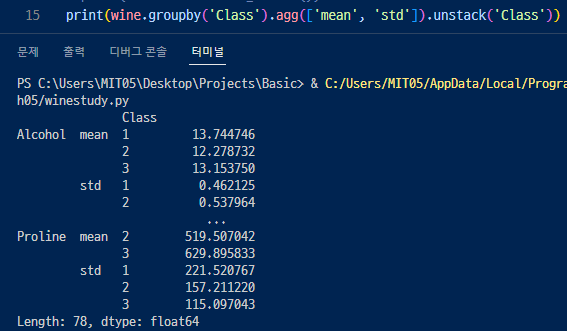
▶ groupby로 묶어서 평균과 표준편차도 각 컬럼마다 확인해볼 수 있다.
<데이터 모델링>
- 데이터 훈련을 위해 데이터 값과 라벨 값을 정해주었다.

▼ 그리고 훈련데이터 / 테스트 데이터 나누고 ( 7:3이니까 테스트사이즈 0.3 고정값나왔으면 해서,, random_state)

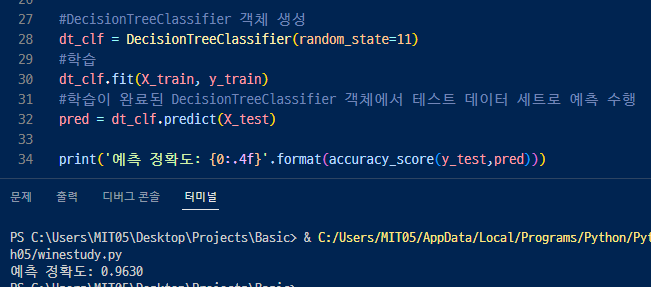
▼ 의사 결정트리의 객체를 생성하고 돌려본 결과 정확도는 0.96
<검증>
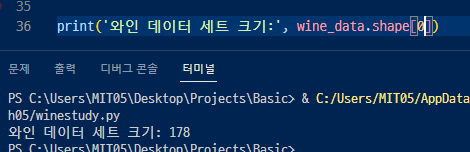
▲ k-fold 검증을 위한 와인 데이터 세트 크기를 확인해보면 178개인데, 그럼 6개로 나누면 되지 않을까..?

▲ 그래서 총 6번을 한 결과 이렇게 정확도가 나온다. 평균 0.83...
좀 더 올리기위해서는 하이퍼파라미터를 조정해서 올려야하는걸까

▶ 이걸 메서드를 이용하면 이렇게 하면 된다는데 그럼 0.91 이 나온다
random_state를 None으로 해놨기 때문에 돌릴때마다 값은 달라진다.
<예측>
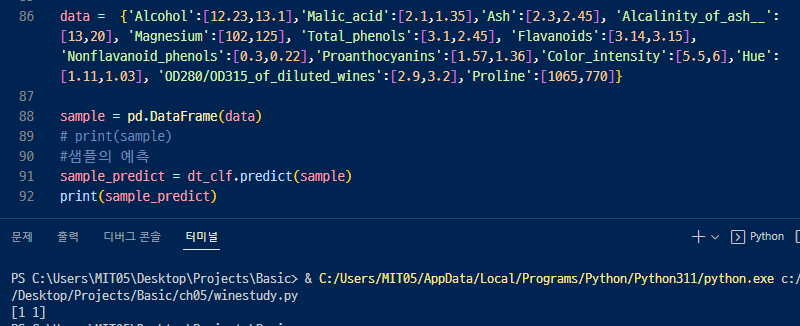
▶ 가상의 값을 2개를 넣었는데 Class 가 1,1 이라고 나왔다!
<상관관계를 확인하고 산점도 그리기>
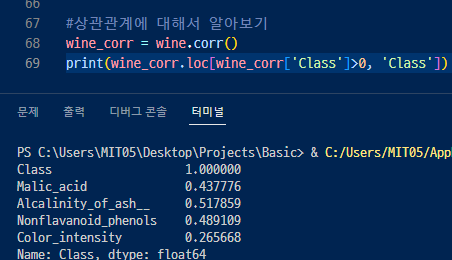
양의 상관관계를 가지는 변수를 확인해보니 color_intensity빼고는 다 비슷비슷하다....
하지만 가장 높은 Alcalinity_of_ash__ 와 Nonflavanoid_phenols 가 가장 영향을 크게 주는 변수다.
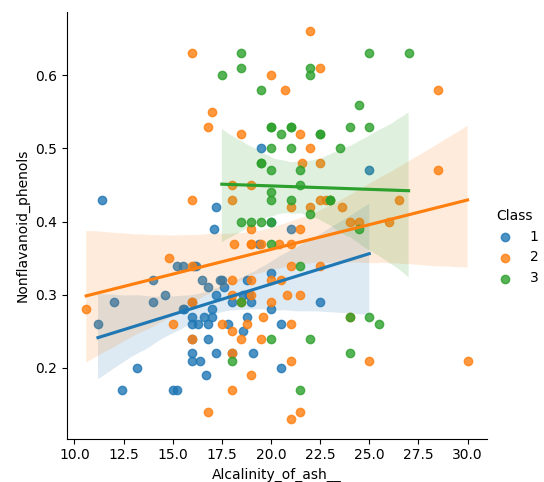
그래서 이 두개를 가지고 산점도 그래프를 그려보았다.
▼2개의 변수로 Class가 어떻게 나뉘어질것인가!

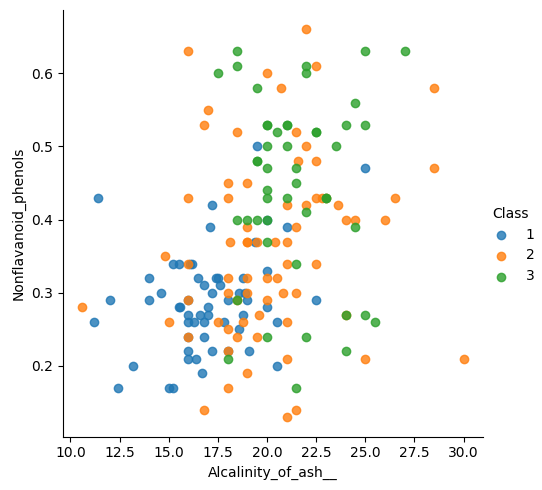
▼ 2개의 변수의 상관관계를 시각화 하는 것 중에 catplot도 있길래 해봄

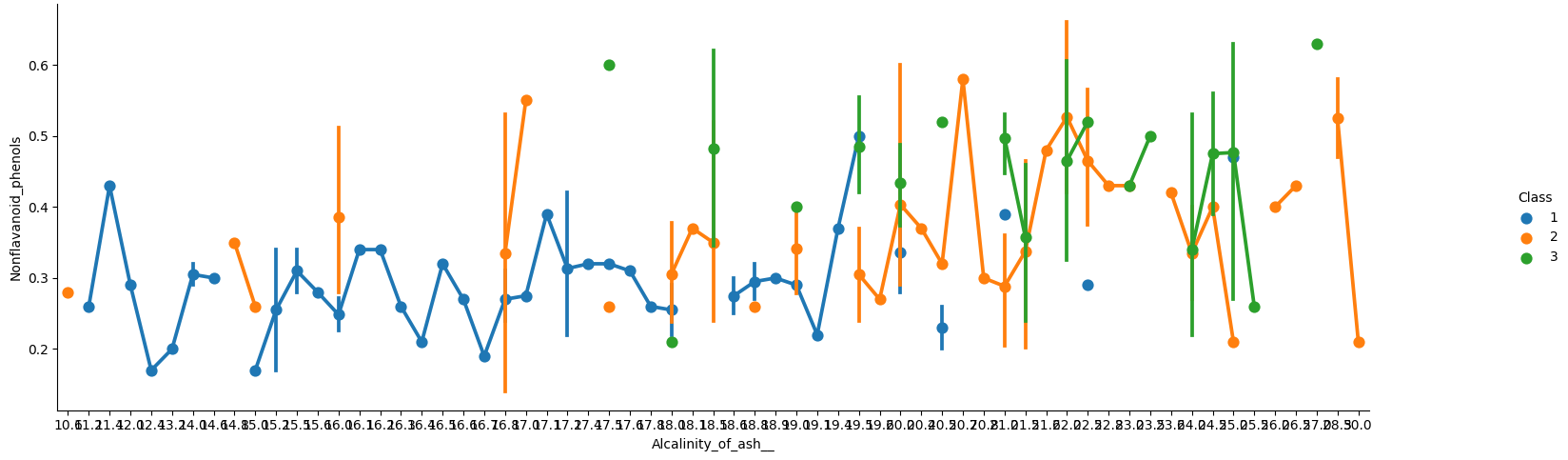
▷▷▷▷ 산점도와 catplot를 보면 알 수 있듯이 2개의 변수만으로는 Class를 명확하게 결정하기 어렵다.
▶ 그리고 수업시간에 배운 pairplot도 사용해서 상관 분석 시각화도 해보았다.
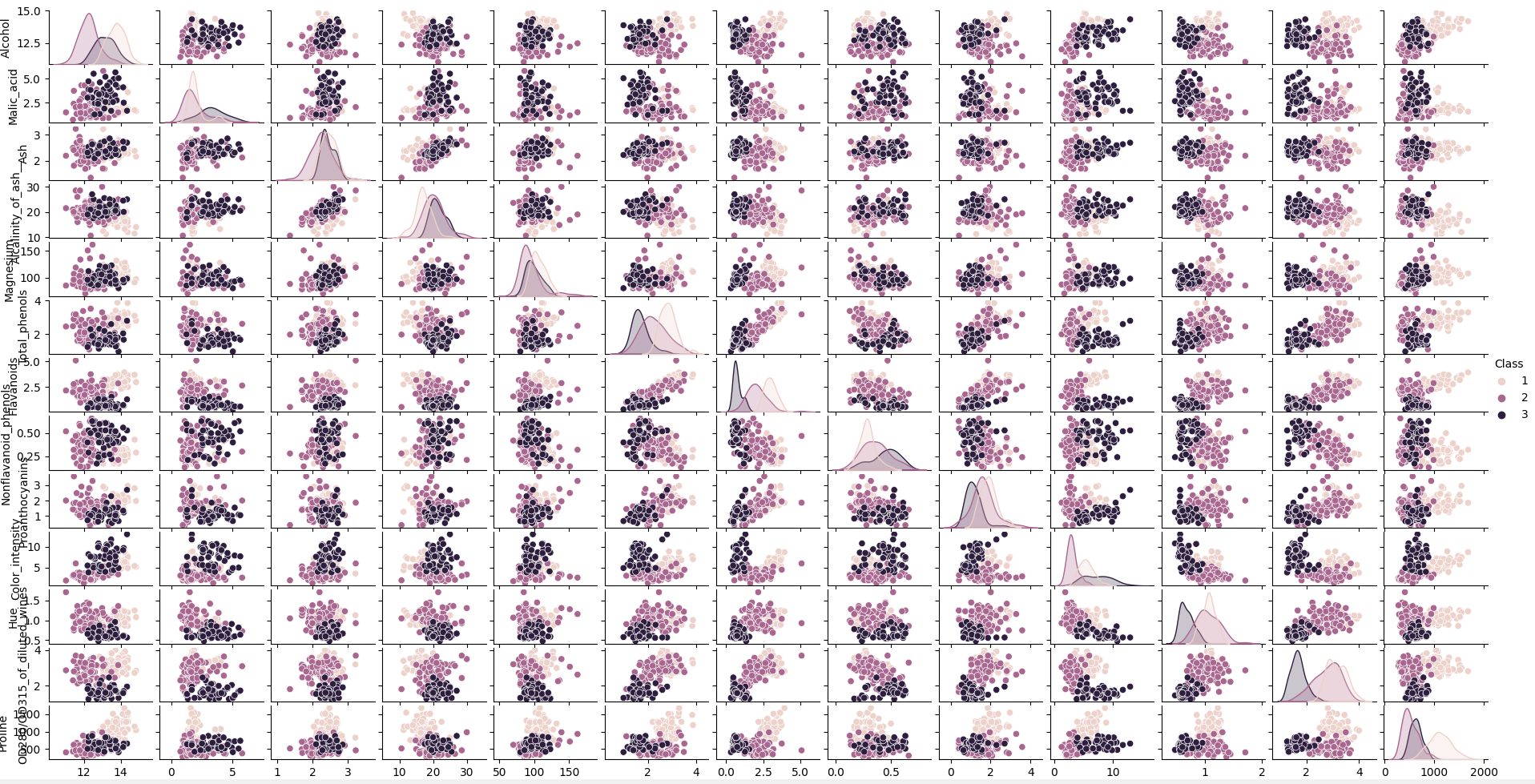
<교수님 피드백>
- 방식이나 절차는 GOOD!
- 정확도가 낮은 이유는 데이터의 갯수가 부족해서 정확한 모델을 도출하기 어렵기 때문에.
- 상관계수값이 그렇게 높지 않기 때문에 -> 대부분 0.6 이상이여야지만 있다고 함
- 그래프가 2개의 속성값으로만 나눠지지 않는 이유는 속상값이 1-2개로 결정나는게 아니라 여러개로 결정나는 것이기 때문에 그래프로 정확히 분류되는것도 어려움.
'머신러닝 > 프로젝트' 카테고리의 다른 글
| Proj 보스턴 주택 가격 회귀분석 (0) | 2023.08.09 |
|---|---|
| Proj 타이타닉호 생존율 분석, 상관관계 찾기 (0) | 2023.08.08 |
| Proj 데이터 기술통계 분석/데이터모델링 - 와인 퀄리티 (3) (0) | 2023.08.07 |
| Proj 데이터 기술통계분석 / 데이터 탐색 - 와인 퀄리티 (2) (0) | 2023.08.07 |
| Proj 데이터 기술통계 분석/ 개요, 데이터 준비 - 와인 퀄리티 (1) (0) | 2023.08.07 |



