*판다스 : csv 파일을 읽고 처리하는데 유용한 함수를 많이 제공함.
csv 파일을 읽어서 데이터프레임DataFrame이라는 표 형식 데이터(tabular data)로 저장함.
▷1차원 데이터 구조 Series , 2차원 데이터가 DataFrame
▷recode = 데이터가 있어서 의미있는 행

*DateFrame만들기 : 리스트, 딕셔너리를 이용해 여러개의 데이터를 변수에 담거나 csv, 엑셀로 불러와서

▼ 링크까지 잡아서 불러올때, syntax error 가 뜰수있음. encoding안써도돼...기본이니..
고칠 수 있는 방법은 3가지(1. \ > / 로 바꿔주기 2. 링크 따옴표 앞에 r 을 붙여서 읽어주기,3. \만 있으면 특수문자로 인식할 수 있으니 \\두개를 써서 이건 특수문자 아니여 라고 알려주기)
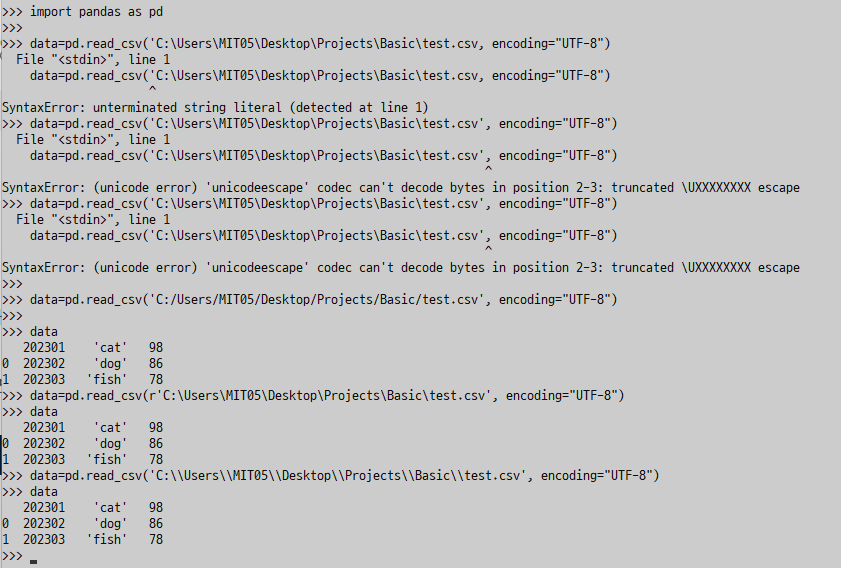
* read_csv() : csv 파일을 읽을때 쓰는 함수. encoding 매개 변수 설정해주는 것도 잊지말고

** 가끔 DtypeWarning 이라는 오류가 발생하는데, 데이터 타입이 자동으로 파악한 타입과 달라지면 경고가 발생함
▶ low_memory=False 로 지정해 파일을 한번에 읽으면 정상적으로 코드 실행이 됨.
▷ 다만 한번에 모두 읽기 때문에 많은 메모리를 사용함.
이럴땐 dtype 매개변수로 데이터 타입을 설정해주느것도 좋음. 이런식으로 ▼

* head() 메서드 : 데이터프레임의 처음 5개 행을 확인할 수 있음. / tail() 은 마지막 줄 5개

▲ 위에 csv 파일을 파이썬을 이용하여 ▼ 아래 처럼 출력
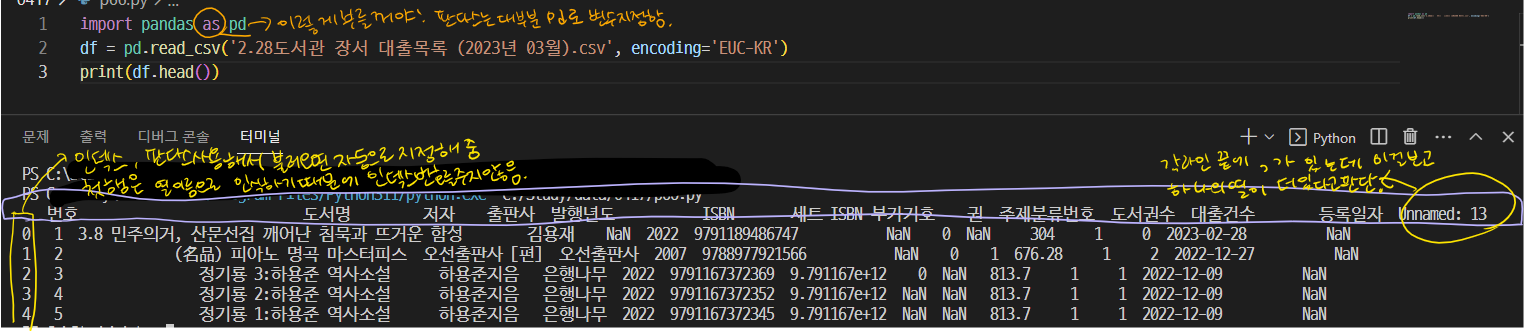
* csv 파일의 첫 행이 열 이름이 아니라면 header 매개변수를 none으로 지정하고 names 매개변수에 열 이름 리스트를 따로 전달해주자. (예시해보자..)
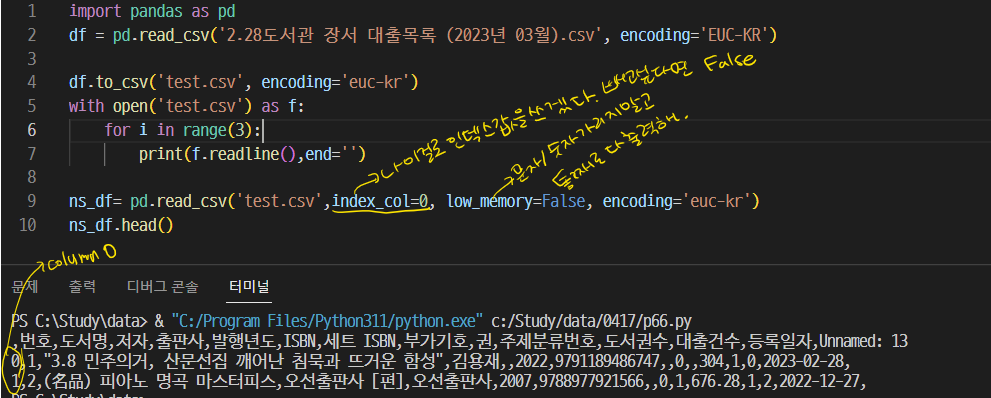
*to_csv() : 데이터프레임을 csv 파일로 저장하기.

▼ to_csv() 메서드로 csv로 저장할 때 인코딩 매개 변수를 사용하고 난 후 / 에러 고침
▷ json으로 저장하려면 to_json... 엑셀이라면 to_excel...

*index_col 매개변수 / index = False = 인덱스가 기존에 있을때/ 안쓰고 싶을때
'데이터분석 > Pandas&Numpy' 카테고리의 다른 글
| 벡터와 넘파이 (8) | 2023.05.08 |
|---|---|
| pandas 잘못된 데이터 수정하기- 누락된 값 NaN, 잘못된 값을 바꾸기 (0) | 2023.04.30 |
| pandas 데이터프레임 불필요한 데이터 제거 및 정리 자세하게 (0) | 2023.04.30 |
| pandas 데이터프레임 불필요한 데이터 제거 및 정리 예제 1번 (2) | 2023.04.24 |
| 넘파이 Numpy (0) | 2023.04.18 |



