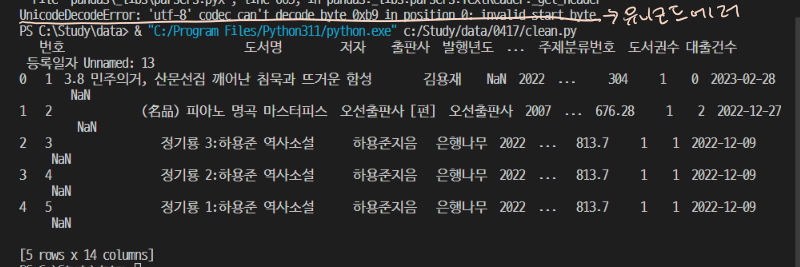
- 데이터를 정제하기 위해 CSV 파일 불러오기,,,
하다보면 'UnicodeDecodeError: 'utf-8' codec can't decode byte 0xb9 in position 0: invalid start byte' 라는
에러가 뜰 수 있는데 이것은 바로 csv가 utf-8이 아닌 'euc-kr'(주로 이거)나 'cp949' 로 되어 있기 때문...!
이럴땐 뒤에 encoding='euc-kr'라고 적어주면 정상적으로 읽어준다.
- 어쨌든 정제하려면 행이야 순서대로 인덱스 번호가 주어진다지만..!
열은 어떻게 쉽게 불러와서 정리할 수 있을까.

열이름에도 인덱스 번호가 주어진다. DF.columns() 메소드를 사용하면
열이름(인덱스이름)이 무엇이 있는지 알려주고, 처음부터 0번..! 헷갈리면 인덱스번호를 붙여서 확인도 가능하다.
- columns 속성은 판다스의 Index 클래스 객체
▶ 판다스 배열 성격의 객체는 어떤 값과 비교할 때 자동으로 배열에 있는 모든 원소와 하나씩 비교해준다.
▷ 이것이 바로 원소별 비교, element-wise comparison ▼ 이렇다고 함

이라는 columns 속성과 비교해서 비교연산자를 사용하면
[ True False True True True True True True True True True True True True]
▶ 이런식으로 반환된 결과 가 나옴. ▶▶ 그것이 바로 넘파이 배열 Numpy array
- 이러한 내용을 토대로 원하는 행만 제외하고 다른 변수에 저장하고 불러오면 원하는 열만 제외 가능.
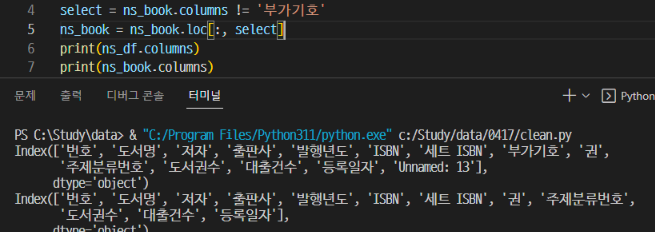
△ 짠 사라졌다 '^'
- 또 다르게 원하지 않는 열을 삭제 하는 방법. drop()
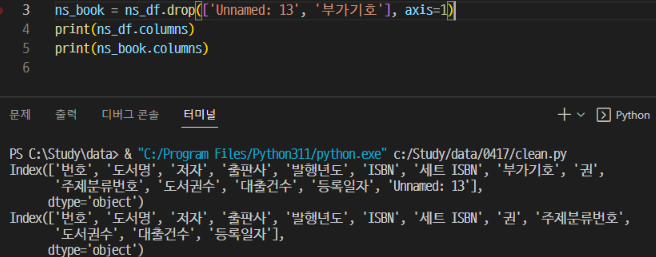
▶ 맨 뒤에 inplace=True를 적으면 선택한 데이터 프레임에 덮어쓰기 (변수 따로 지정안해줘도됨)
'데이터분석 > Pandas&Numpy' 카테고리의 다른 글
| 벡터와 넘파이 (8) | 2023.05.08 |
|---|---|
| pandas 잘못된 데이터 수정하기- 누락된 값 NaN, 잘못된 값을 바꾸기 (0) | 2023.04.30 |
| pandas 데이터프레임 불필요한 데이터 제거 및 정리 예제 1번 (2) | 2023.04.24 |
| 넘파이 Numpy (0) | 2023.04.18 |
| 판다스 pandas as pd (0) | 2023.04.18 |



