1. make_classification() 으로 데이터 X와 라벨 y를 생성하고
2. train_test_split()으로 학습데이터와 테스트 데이터를 나눈다.
3. LogisticRegression, LinearSVC, SVC, DecisionTreeClassifier, RandomForestClassifier를 import한 후
모델을 딕셔너리를 이용해 구축한다.
4. for문으로 모델을 학습시키고 정확도를 출력한다.
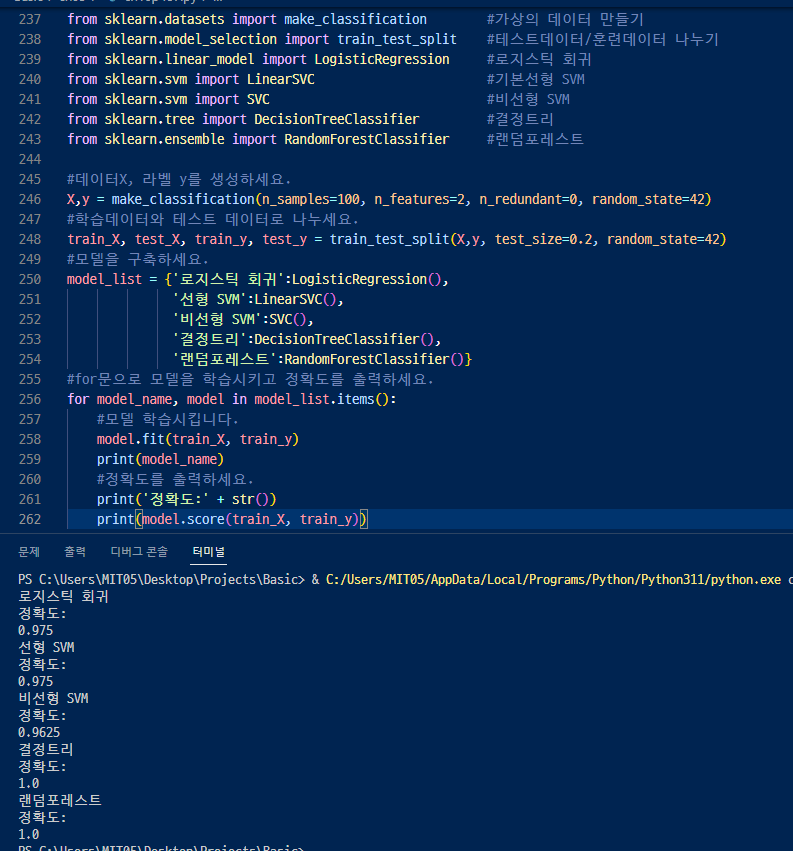
▷랜덤 포레스트랑 결정트리의 정확도가 가장 높다(1.0이니..ㅎ)
▷그래서 앞에서 했던 버섯데이터에도 해봤다.


▶ 여기서는 결정트리, 랜덤포레스트가 미세하게 높게 나왔고 비선현 SVM도 만만치 않게 높게 나왔다.
0.0002가 높으니까 크게 차이나지 않는게 아닐까..?
'머신러닝 > 개념익히기' 카테고리의 다른 글
| 머신러닝 scikit-learn, 머신러닝 프로세스 간단히 알고가기 (0) | 2023.07.21 |
|---|---|
| 머신러닝 하이퍼파라미터 (0) | 2023.07.20 |
| 머신러닝 랜덤포레스트 / k-NN (0) | 2023.07.19 |
| 결정트리, decision tree (0) | 2023.07.18 |
| 기본 선형 SVM (0) | 2023.07.18 |



