캐글 - 타이타닉으로 연습하는 판다스
1. 데이터 다운 받고 DataFrame으로 불러오기
https://www.kaggle.com/c/titanic/data?select=train.csv
에서 먼저 코드를 다운로드 받는다.

read_csv()는 별다른 파라미터 지정이 없으면 파일의 맨 처음 row를 컬럼명으로 인지한다.
그리고 맨 왼쪽에는 판다스의 Index 객체들임.
(모든 DataFrame 내의 데이터는 생성되는 순간 고유의 Index 값을 가지기 때문이다.
>> 이것이 바로 RDBMS의 PK와 유사하게 식별하는 역할)
* DataFrame의 크기를 알려면 .shape 메서드.
여기에는 891행(row) 12열(column)의 데이터가 들어있다.
▶ 행과 열을 튜플 형태로 반환한다.


* DataFrame의 정보들을 알려면 info() 나 describe() 메서드를 사용해서 조회가 가능하다.
▶ 먼저 info( ) 메서드를 사용해보면

맨 위에 index 범위와 열 갯수를 알려주고,
column 별 데이터 타입을 나타낸다. object는 문자열타입으로 생각해도 무방.
그리고 몇개의 데이터가 null 값이 아닌지(누락값이 아닌지) 나타낸다.
▶ 여기서 Age는 714개가 non-null이니.. 891개 중 177개가 누락됐다는 얘기
그래서 맨 마지막에 dtypes: 를 통해 전체 12개의 컬럼 중에서 타입 별로 몇개씩인지 알려준다.
* describe() 메서드는 숫자형 컬럼의 분포도, 평균값, 최댓값, 최솟값 등 나타낸다.
▶ 데이터의 분포도를 아는 것은 머신러닝 알고리즘 성능을 향상시키는 중요한 요소 중 하나.
▷ ex. 회귀에서 결정 값이 정규 분포를 이루지 않고 특정 값으로 왜곡 되었거나 데이터값이 이상치가 많으면 예측 성능이 저하됨. 물론 이걸로 정확한 분포도를 알기엔 힘들지만 개략적으로 분포도를 확인할 수 있음.

count 는 Not Null 인 데이터 갯수, mean은 데이터 평균값, std는 표준 편차, min은 최솟값, max는 최댓값.
25%는 25 percentile 값, 50%는 50 percentile, 75%는 75 percentile값.
그리고 무엇보다 여기에 값이 나온 컬럼은 숫자형 컬럼이라는것..!
▶ 여기서 PassengerID는 승객 ID이기 때문에 분석을 위해서는 의미 없음. 그리고 survived 는 min이 0, max가 1, 그리고 25%, 50%도 0인걸로 봐서는 0과 1로 이루어진 숫자형 카테고리일테니 의미 없음. Pclass도 min이 1, 25% 2, 50%와 75%는 3, max도 3이기 때문에 아마 1,2,3으로 이루어진 숫자형 카테고리 일듯..!
▷ 그래서 확인을 위해! Pclass의 데이터 분포도를 확인하기 위해 value_counts() 메서드를 써보자!

▷ 확인해보니 1,2,3으로 데이터값이 이루어져있다. 이러한 하나의 열의 타입을 확인해보면 Series인것을 확인할 수 있다.

▶ Series는 <Index + 한개의 컬럼> 으로 되어 있고, Series들이 모여 DataFrame이 된다.

▶Pclass 열만 저장한 Series를 불러오면 인덱스값이 0, 1, 2, 3 이 되는데 value_counts()메서드를 써서 불러오게 되면 인덱스값이 3,1,2로 되어있는걸로 보인다. 유일한 값이라면 인덱스로 된다는 사실...! 그래서 pclass_value[3]이라고 인덱스 3을 불러와주면, 순차적인 인덱스 3의 값인 1(첫번째 titanic_pclass 결과 값에서 볼 수 있음) 이 나오는게 아니라 pclass_value에서 3을 불러와서 '3'의 값을 가지고 있는 데이터 수가 491개라는 값을 받을 수 있다. (대신 무조건 인덱스는 고유성이 보장되어야함, 중요 별표 백만개)
▷ *중요* value_counts() 메서드는 Null 값을 무시하고 내놓기 때문에 NaN(Null)이 많다면 데이터 분석에 영향을 끼칠 수 있다. 그래서 dropna 인자를 적어줘야한다. 디폴트값은 True이고, NaN을 무시하고 건수를 계산하게 된다.

▶ 원본 데이터 갯수는 891개. 원본 데이터에서 'Embarked' 데이터 갯수를 dropna=True(기본값)으로 불러왔을 때 644+168+77= 889개 이므로 2개의 누락값이 포함되지 않은 것을 확인할 수 있다. 그래서 dropna=False로 불러와주니 NaN이라는 데이터 갯수의 내용까지 출력해주는 것을 확인할 수 있다.
*DataFrame의 칼럼 데이터 세트 생성과 수정 역시 [ ] 연산자로 쉽게 할 수 있다.

numpy의 ndarray에 상숫값을 할당할 때 모든 배열 값에 일괄 적용되는 것 처럼 뒤에 스칼렛 값을 연산해주면 모든 행의 값에 연산되어 새로운 컬럼의 Series를 만들 수 있다. 업데이트도 마찬가지. 열 이름을 다시 불러오고 새로운 값을 넣어주면 일괄적으로 업데이트가 된다.
* DataFrame에서 데이터의 삭제는 drop( ) 메서드를 이용한다.
df.drop (labels=None, axis=0, index=None, columns=None, level=None, inplace=False, errors='raise')
여기서 중요한 파라미터는 labels와 axis, inplace이다. labels는 원하는 컬럼명(여러개면 리스트로 전달)을 입력. 그리고 axis는 잘 알고 있다 싶이 축 방향이다. (0은 row 방향 축, 1은 column 방향 축)
그래서 위에서 추가했던 'Age_0'을 삭제해보면

▶ titanic_drop_df이라는 변수에 선언해주고 출력해보니 'Age_0' 칼럼이 삭제된 것을 확인할 수 있다.

▷ 하지만 titanic_df 원본에는 아직 'Age_0'칼럼이 삭제되지 않은 것을 확인할 수 있다.
▶ 바로 inplace = False(default) 로 설정되었기 때문이다. inplace가 false면 원본의 데이터는 삭제 하지 않는다. 따라서 새로 변수로 선언한 titanic_drop_df 라는 곳에서만 삭제되었지, 원본에서는 그대로 잘 지워지지 않고 있다.
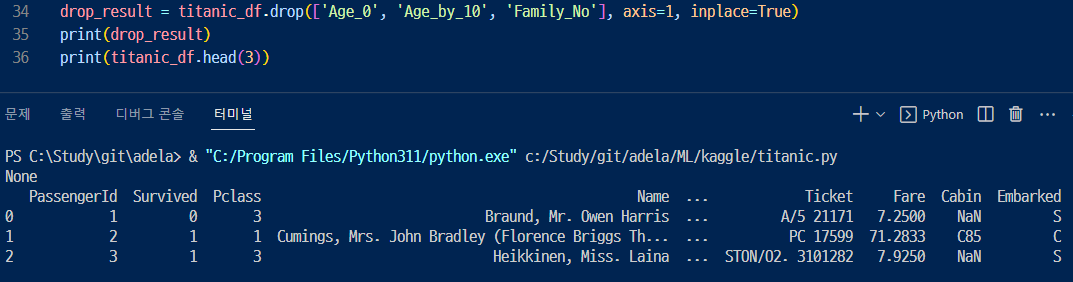
▶ 그래서 리스트로 삭제하고자하는 컬럼명을 전달한 후에 inplace=True로 해서 삭제해보았다. 삭제한 값은 위에서와 같이 drop_result라는 변수에 새롭게 선언해주었는데 출력하니 None만 나왔다. 왜냐하면 inplace=True로 원본 값이 변했기 때문에 반환값이 None이 되었다. inplace=True로 설정하고 반환 값을 다시 저장하면 안된다는것을 확인할 수 있다.
▶axis = 0 을 설정해서 로우, 행을 삭제해보자!
▷ set_option은 기존 데이터프레임의 옵션값을 재세팅하는건데... 되게 뭐가 많다 많어 자세한 내용은 공식 사이트..ㄱ
https://pandas.pydata.org/docs/reference/api/pandas.set_option.html?highlight=set_option
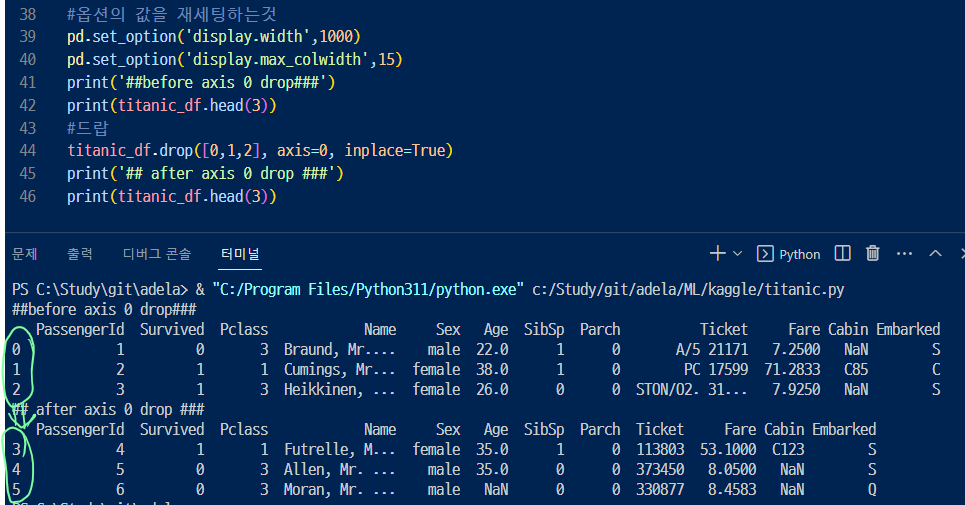
▶ axis= 0 으로 해서 삭제하고 head를 불러와보니 0,1,2로 시작하던 인덱스가 3,4,5로 시작하고 있다.
'데이터분석 > Pandas&Numpy' 카테고리의 다른 글
| pandas DataFrame과 Series의 정렬 (0) | 2023.07.06 |
|---|---|
| pandas iloc, loc, boolean Indexing/Slicing (0) | 2023.07.06 |
| pandas apply 메서드 사용해보기 (0) | 2023.07.05 |
| Numpy tolist 메서드 (0) | 2023.07.04 |
| pandas 특수한 자료형 - 카테고리 (0) | 2023.07.03 |



