* XML : eXtensible Markup Language, (확장된 HTML)
- element 들이 계층 구조를 이루면서 정보를 표현
- 태그 이름은 영문자와 숫자로 사용, 시작태그와 종료태그가 있고 이름은 같아야 (HTML 과 유사)

* findtext() 메서드 : 해당하는 자식 element를 탐색해 자동으로 텍스트로 반환됨.
- 찾으려는 태그 이름을 넣어주니 자동으로 해당 element를 찾아 텍스트를 반환함.
#XML 문자열 형식
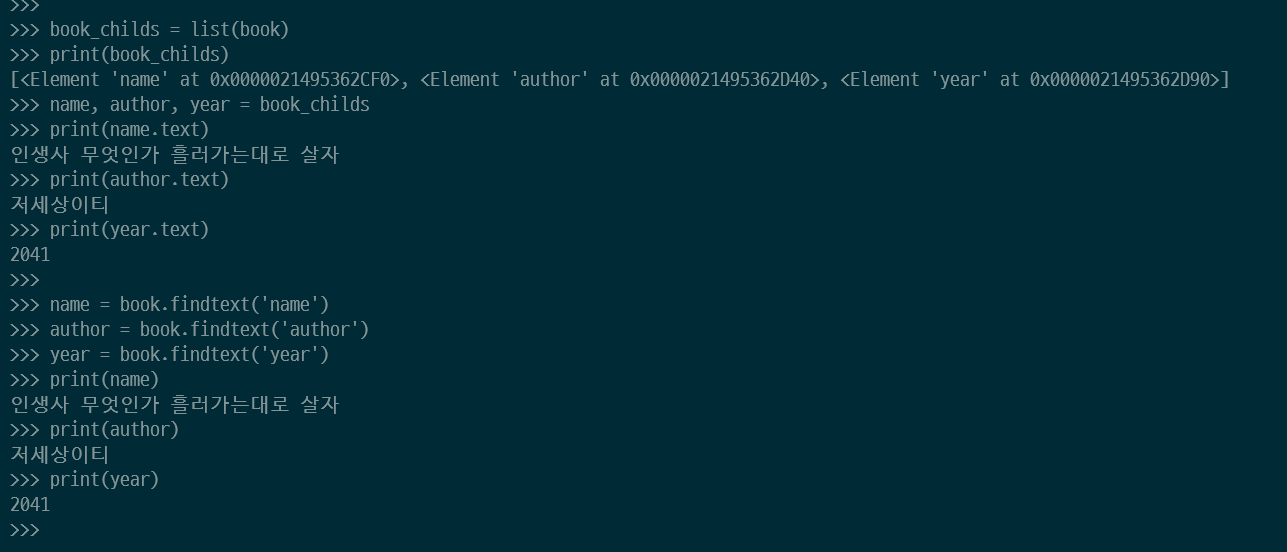
x_str = """
<book>
<name>이거슨 삼에대한 책임다</name>
<author>접니다</author>
<year>2022</year>
</book>
"""
import xml.etree.ElementTree as et
book = et.fromstring(x_str) #XML 데이터를 파이썬 Element 객체로 변환
print(type(book)) #book 변수의 타입 출력
print(book.tag) #book 태그의 타입 출력
book_childs = list(book) #book 객체를 리스트로 변환
print(book_childs)
name, author, year = book_childs #데이터 언패킹 = 맵핑 mapping
print(name.text)
print(author.text)
print(year.text)
#findtext()메서드 사용
name = book.findtext('name')
author = book.findtext('author')
year = book.findtext('year')
print(name)
print(author)
print(year)
x2_str = """
<books>
<book>
<name>이것은 삼에대한 책</name>
<author>접니다</author>
<year>2022</year>
</book>
<book>
<name>저거슨 요것에 대한 책</name>
<author>납니다</author>
<year>2020</year>
</book>
</books>
"""
books = et.fromstring(x2_str)
print(books.tag) #x2_str 의 부모 요소를 찾아서 출력
for book in books.findall('book'):
name = book.findtext('name')
author = book.findtext('author')
year = book.findtext('year')
print(name)
print(author)
print(year)
print()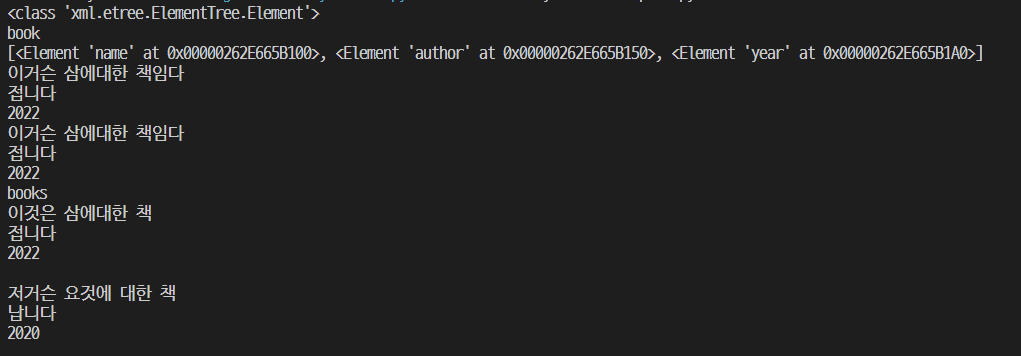
ㅎ...일단 여기까지 투비컨티뉴..
'데이터분석' 카테고리의 다른 글
| 데이터 프레임 행과 열 선택하기 (0) | 2023.04.19 |
|---|---|
| API (1) | 2023.04.18 |
| JSON (0) | 2023.04.18 |
| API (0) | 2023.04.18 |
| 데이터 분석의 시작- CSV파일 파이썬으로 출력하기 (0) | 2023.04.17 |



