| 목표 | 사용자 행동 인식 데이터 세트를 활용해 예측 분류 수행 |
| 데이터 준비 | 30명에게 스마트폰 센서를 장착한 뒤 사람의 동작과 관련된 여러가지 피처를 수집한 데이터 https://www.kaggle.com/datasets/uciml/human-activity-recognition-with-smartphones/ |
| 분석 모델 구축 | 결정 트리 Decision Tree |
<데이터 준비 그리고 EDA 그리고 전처리>
먼저 데이터를 불러옴
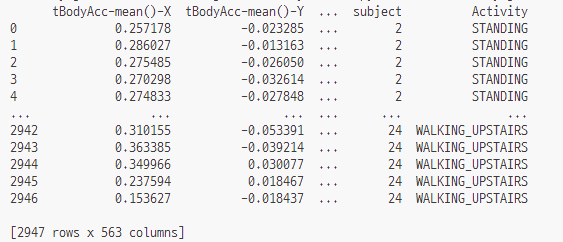
그리고 컬럼 값(피처명)도 불러옴

피처명을 보면 X, Y, Z 이런식으로 나와 있는데,
인체의 움직임과 관련된 속성의 평균(mean)과 표준편차(std)가 X,Y,Z축 값으로 되어 있는 듯 함
그러다보니 중복되는 피처명들이 있을 수도 있음 (563개나 되니까)
그럼 오류가 날 수 있으니까 체크체크

체크해봤을 때 아무것도 나오지 않고
바로 '중복된 컬럼 체크 종료' 로 끝났다. 아무런 중복된 컬럼이 없다.
info () 했을 때

총 2,947개의 데이터.
컬럼 563개. 대부분의 값이 float이고 object가 한개 있다.
아까 데이터를 살펴봤을 때 'Activity'가 Object인듯
describe() 하면

음. 일단 561개의 컬럼이 float이기 때문에 ㅎㅎㅎㅎㅎㅎㅎ
보는 의미가 없는 듯. 그리고 행동하는 좌표? 니까 큰 의미가 없는 것같다.

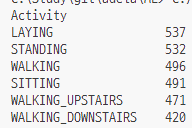
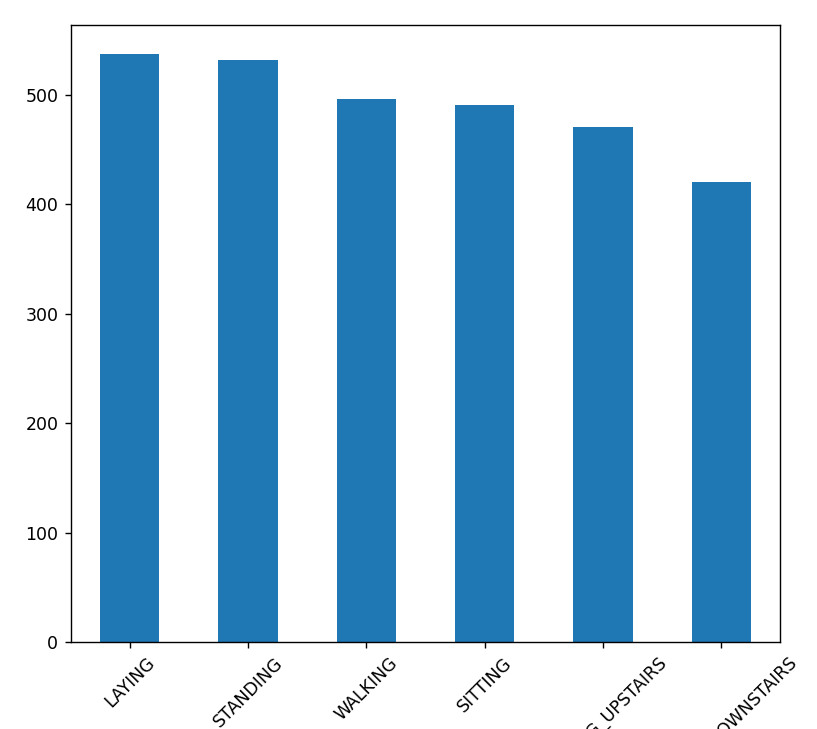
뭐 그래... 나름 고르게 분포가 되어 있다고 생각함
(100개차이나면 많이 차이나는건가)
그런데 보니까 train.csv 파일과 test.csv 이라는 파일이 따로 있음.
train 하고 test로 성능 평가하는것도 생각하긴 했는데
일단은 합쳐서 하나로 학습해보기로 결정!
그래서 concat을 써서 두개 합치고
중복된 컬럼이 있는지 다시 한번 확인하고
데이터 분포도 다시 확인
(위의 내용 다시 반복한거임)
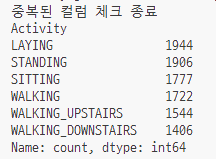
데이터가 늘었다
<모델 구축>

정확도는 0.94가 나온다.
기본 하이퍼파라미터로 했기 때문에 하이퍼파라미터를 조정해보쟈
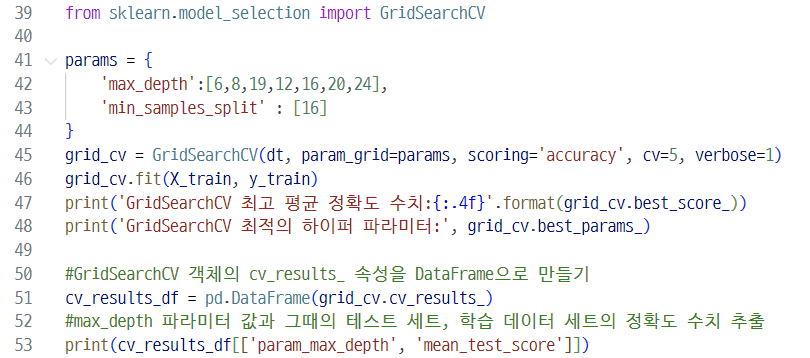
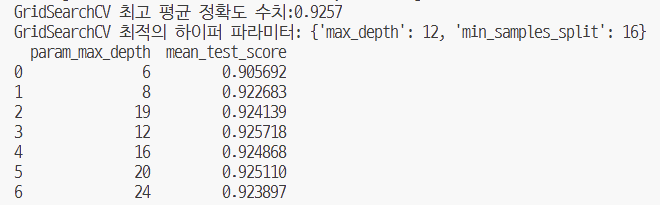
해보니까 max_depth이 12일때 가장 좋은 성능이 나오긴했는데,,
사실 다 비슷비슷해서 ㅋㅋㅋㅋㅠㅠㅠ
그리고 아까 0.94가 제일 높게 나왔기 때문에
기본 하이퍼파라미터로 한게 제일 높았다!
'머신러닝 > 프로젝트' 카테고리의 다른 글
| Proj 레스토랑의 웨이터 팁 분석 및 예측 (0) | 2023.12.29 |
|---|---|
| Proj 구글 스토어 앱 데이터 분석을 통한 평점 예측 (2) (1) | 2023.11.27 |
| Proj 구글 스토어 앱 데이터 분석을 통한 평점 예측 (1) (7) | 2023.11.26 |
| Proj 피마 인디언 당뇨병 예측 (0) | 2023.10.24 |
| Proj 콤프레샤 모터의 이상감지 (2) | 2023.08.21 |



