정확도
= 예측결과와 실제 값이 동일한 건수 / 전체 데이터 수
= (TN + TP) / (TN + FP + FN + TP)
▶ 불균형한 이진 분류 데이터 세트에서는 한쪽 데이터가 매우 적어서 예측 정확도가 높아지는 경향이 발생
▶ 분류 모델의 성능을 측정할 수 있는 한 가지 요소일 뿐, 하지만 정확도만으로는 신뢰도가 떨어질 수 있으니
더 선호되는 정밀도Precision와 재현율Recall에 대해 알아보자
정밀도 / 재현율 = Positive 데이터 세트의 예측 성능에 좀 더 초점을 맞춘 평가 지표
▶좀더 정확히 : https://dev-adela.tistory.com/162
혼동행렬 / 성능평가지표
- 각테스트 데이터에 대한 모델의 예측 결과를 4가지 관점에서 분류 > 참 양성,TP(True Positive) : 양성 클래스로 예측되었고 결과도 양성 클래스인 개수 > 참 음성,TN(True Negative) : 음성 클래스로 예측
dev-adela.tistory.com
정밀도 = TP / (FP + TP)
▶ 상대적으로 더 중요한 지표인 경우는 Negative인 데이터 예측을 Positive로 잘못 판단하게 되면
업무상 큰 영향이 발생하는 경우 ex.스팸 메일 분류 등
재현율 = TP / ( FN + TP)
= 민감도 Sensitivity 또는 TPR(True Positive Rate)라고도 불림
▶ 실제 Positive 데이터를 Negative로 판단하게 되면 업무상 큰 영향이 되는 경우
ex . 암 판단모델, 보험사기, 금융 사기 적발 모델 등
▶ ▶ ▶ ▶ 둘 다 모두 TP를 높이는데 초점을 맞추지만, 재현율을 FN을 낮추는데, 정밀도는 FP를 낮추는데 초점
그래서 서로 보완적인 지표로 분류의 성능을 평가하는데 적용
물론 가장 좋은건 재현율, 정밀도 모두 높은 수치를 얻는 것...🙂
코드로 풀어서 보자면
일단, confusion matrix, accuracy, precision, recall(sensitivity) 구하는 함수를 만들어줌

그리고 로지스틱 회귀로 모델을 구축하고 평가 수행..!
solver = liblinear는 작은 데이터 세트의 이진 분류인 경우,
최적화 알고리즘 유형을 지정해 성능이 약간 더 좋을 수 있다.
(기본값은 lbfgs , 이건 데이터셋이 크고 다중분류인 경우 적합)

정밀도 / 재현율 트레이드 오프
▶ 둘 중 하나를 특별히 강조해야할 때, 결정 임곗값(Threshold)을 조정해 수치를 높일 수 있음.
▷ 벗뜨, 어느 한 쪽을 강제로 높이면 다른 하나는 떨어지기 쉽다. 이를 Trade-off라고 부름.
- 분류 알고리즘은 예측 데잍터가 특정 레이블에 속하는지 계산하기 위해 개별 레이블별로 결정 확률을 구함.
그리고 예측 확률이 큰 레이블값으로 예측하게 됨.
예를 들어 0이 될 확률이 10%, 1이 될 확률이 90% 라면 1이됨.
▶ 이렇게 예측 확률을 반환하는 메서드는 predict_proba()

127. Shape에서 표본 갯수가 179개이고 2개의 클래스값유형이 있다는 것.(이진 분류라는것)
128. 각 row는 예측 확률,
132. 0이 될 확률은 0.15, 1이될 확률은 0.84니까 1 이런식으로 해석 가능
<predict_proba() 호출 결과로 분류 결정 임곗값을 알 수 있었는데,
어떻게 정밀도/재현율 트레이드오프를 구현했는지 이해해보자>
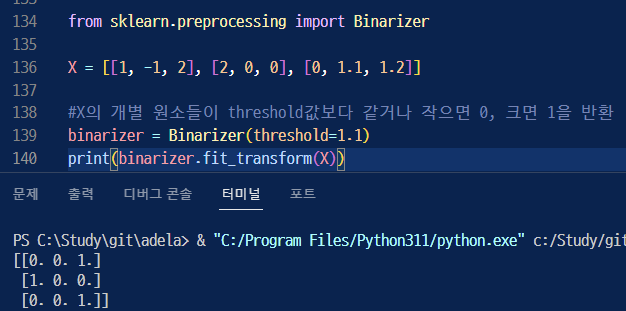
Binarizer 클래스를 사용!
139. Binarizer의 threshold 값이 1.1 보다 같거나 작으면 0, 크면 1로 변환해 반환
<<< 아까 위에서 했던 타이타닉 데이터로 해보면>>>>>>
▶ 임곗값을 0.5로 하고 Positive 클래스 컬럼만 추출해서 적용시켜봤을때

▶임곗값을 0.4로 바꾸니까?

재현율이 올라가고 정밀도가 떨어졌다.
▶ ▶ ▶ 이유 : 임곗값은 Positive 예측값을 결정하는 확률의 기준이기 때문에.
낮출수록 True값이 많아지게 된다. ( Positive 예측을 좀 더 너그럽게 하기 때문에)
<임계값을 0.4부터 0.6까지 0.05씩 증가시키며 평가 지표 봐보기>

임계값이 올라갈수록 정밀도는 올라가고 재현율을 떨어짐. 둘다 괜찮은 수치로 하려면 0.45가 적당해보임
▶ precision_recall_curve() 는 임곗값 변화에 따른 평가 지표 값을 알아보는 API

그래프로 그려봅시다 😬

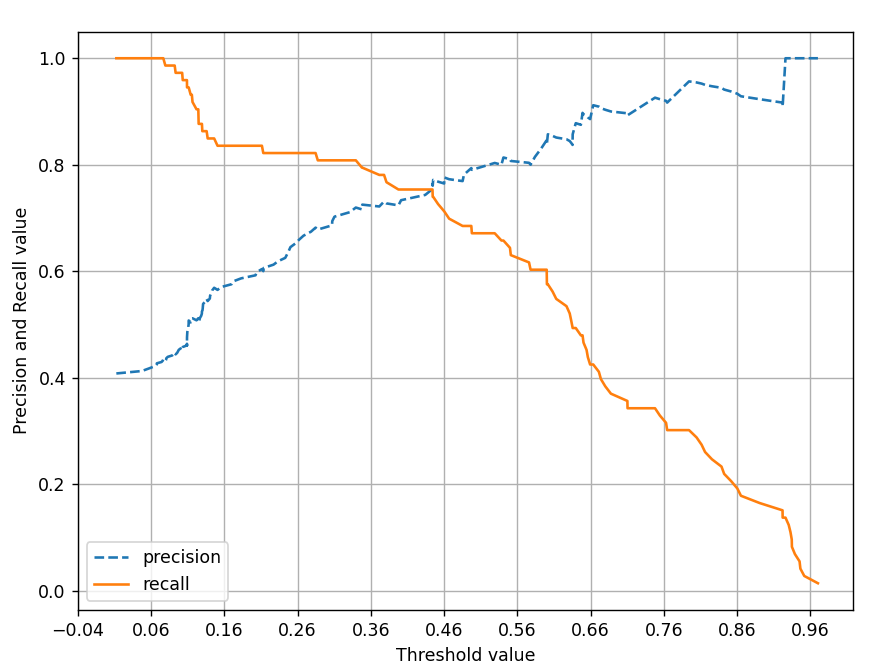
정밀도는 점선, 재현율은 실선.
그래프를 보면 알 수 있듯이 두개의 값은 트레이드오프관계임.
그래서 보면 0.45부분에서 두개 점이 만나는걸 확인할 수 있는데,
두개의 값이 비슷해지는 부분임.
임곗값을 변경함에 따라 정밀도와 재현율의 수치가 변경되는 것을 볼 수 있음.
그래서 업무 환경에 맞게 상호 보완할 수 있는 수준에서 적용되어야 함.
'머신러닝 > 개념익히기' 카테고리의 다른 글
| ML 앙상블 Ensemble- 랜덤포레스트, RandomForest (0) | 2023.11.02 |
|---|---|
| ML F1 score, ROC 곡선과 AUC (0) | 2023.10.23 |
| ML 분류 평가지표 - 정확도 Accuracy (0) | 2023.10.19 |
| 머신러닝 앙상블 학습, 보팅 배깅 부스팅 (0) | 2023.08.30 |
| 머신러닝 교차검증을 보다 간편하게 해주는, cross_val_score() (0) | 2023.08.22 |



