<OLTP vs OLAP>
- OLTP(On-Line Transcation Processing) : 네트워크상의 여러 이용자가 실시간으로 데이터베이스의 데이터를 갱신하거나 조회하는 등의 단위작업을 처리하는 방식 ex)은행에서 입출금 등이 일어날때
- OLAP (On-Line Analytic Processing) : 정보 위주의 처리분석을 의미한다. 의사결정에 활용할 수 있는 정보를 얻을 수 있께 해주는 기술 ex) 판매추이, 구매성향 파악, 재무회계 분석 등을 프로세싱하는것
<CRM 와 SCM>
- CRM : 선별된 고객으로부터 수익을 창출하고 장기적인 고객 관계를 가능케 함으로써 보다 높은 이익을 창출할 수 있는 솔루션
- SCM : 제조, 물류, 유통업체 등 유통 공급망에 참여하는 모든 업체가 협력을 바탕으로 정보기술을 활용, 재고를 최적화하기 위한 솔루션
> SCM과 CRM은 연동되기 때문에 상호 밀접한 관계 오늘날 CRM은 기존의 목적은 변화되지 않고 방법론에서만 변화하고 있음.
<RTE: Real-Time Enterprise , 실시간 기업>
- 가트너는 RTE를 '최신 정보를 사용해 자사의 핵심 비즈니스 프로세스들의 관리와 실행과정에서 생기는 지연 사태를 지속해서 제거함으로써 경쟁하는 기업'으로 정의
<ERP와 BI>
- ERP : 제조업을 포함한 다양한 비즈니스 분야에서 생산, 구매, 재고, 주문, 공급자와의 거래, 고객서비스 제공 등 주요 프로세스 관리를 돕는 여러 모듈로 구성된 통합 솔루션
- BI (Business Intelligence) : 데이터 기반 의사결정을 지원하기 위한 리포트 중심의 도구
- BA (Business Analytics) : 소프트웨어로 데이터를 분석해 미래를 예측하거나(예측 분석), 특정 접근법을 적용했을 때 발생할 수 있는 일을 내다보는 (처방적 분석) 기술의 도움을 받는 과정이다. 그래서 BA는 고급분석(advanced analytics)라고 불리기도 한다. 의사결정을 위한 통계적이고 수학적인 분석에 초점
<정형 데이터 vs 반정형데이터 vs 비정형 데이터>
| 정형 데이터 Structured Data |
반정형 데이터 Semi-Structured Data |
비정형 데이터 Unstructured - Data |
| - 관계형 DBS의 테이블과 같이 고정된 컬럼에 저장되는 데이터와 파일, 행,열에 의해 데이터의 속성이 구별되는 스프레드시트 형태의 데이터도 있을 수 있다. - 데이터의 스키마를 지원함 > 스키마 구조를 가지고 있어 데이터를 탐색하는 과정이 테이블 탐색, 컬럼구조 탐색, 로우 탐색 순으로 정형화 되어 있음. ex) RDBMS의 테이블들, 스프레드 시트 |
- 데이터 내부에 정형 데이터의 스키마에 해당되는 메타데이터를 가지고 있으며, 일반적으로 파일 형태로 저장된다. - 데이터 구조에 대한 메타정보를 갖고 있기 때문에 어떤 형태를 가진 데이터인지 파악하는것이 중요. - 데이터 내부에 있는 규칙성을 파악해 데이터를 파싱할 수 있는 파싱 규칙을 적용한다. ex)URL형태, HTML, 오픈API, XML, JSON, IOT에서 제공하는 센서데이터 |
- 하나의 데이터가 수집 데이터로 객화되어있음 - 언어 분석이 가능한 텍스트, 이미지, 동영상 같은 멀티미디어 데이터 - html같은 형태로 존재해 반정형 데이터로 구분할 수도 있지만 수집할수도 있어서 명확한 구분 어려움 ex) 동영상, 이미지, 소셜 데이터의 텍스트 |
<데이터웨어하우스>
- 기존의 운용 데이터베이스에 비교하여 의사결정을 지원할 수 있는 분석 정보를 제공함.
- 특징:
1. 데이터의 주제 지향성 : 의사결정에 필요한 주제와 관련된 데이터만 유지하는 주제지향적인 특징
2. 데이터의 통합성 : 데이터가 항상 일괄된 상태를 유지하도록 DB에서 추출한 데이터를 통합하여 저장하는 특징
3. 시계열성 : 데이터간의 시간적 관계나 동향을 분석해 의사결정에 반영할 수 있도록. 시간에 따른 변경을 항상 반영하고 있어야함
4. 비휘발성 : DB는 삽입삭제수정작업이 자주일어나지만 데이터웨어하우스는 읽기 전용의 데이터만 유지한다.
※ 데이터 레이크(Data Lake) : 대용량의 정형 및 비정형 데이터를 저장/접근하는 대규모 저장소.
<데이터 정의 - 존재론vs당위적>- 존재론 : 객관적 사실 fact. 데이터 자체로는 의미가 중요하지 않은 객관적인 사실 - 당위적 : 추론, 예측,전망,추정을 위한 근거(basis)로 기능하는 당위적 특성. 다른 객체와의 상호 관계 속에서 가치를 갖음
<데이터의 정의 - 정성적(qualitative) vs 정량적(quantitative) >- 정성적 : 언어, 문자 등, 자료의 성질과 특징을 자세히 풀어쓰는 방식. ex. 만족도 선호도, 요약, 주관적 결론 등- 정량적 : 수치, 도형, 기호 등 자료를 수치화 하는 것. 정형 데이터, 통계분석, 객관적 결론 등
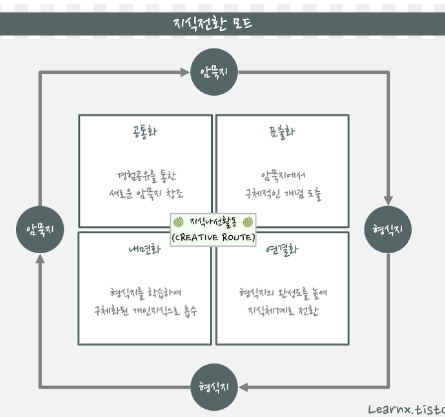
<암묵지 vs 형식지>- 암묵지 : 경험을 통해 획득할 수 있는 지식. 겉으로는 드러나지 않는 상태의 지식- 형식지 : 체계화된 자료 등을 통해서 획득할 수 있는 지식. 문서처럼 외부로 표출되어서 여러 사람이 공유가능<암묵지와 형식지의 상호작용>- 공통화(Socialization) : 암묵지 지식 노하우를 다른 사람에게 알려줌- 표출화(Externalization) : 암묵지 지식 노하우를 책, 교본 형식으로 전환함- 연결화(Combination) : 책, 교본에 자신이 알고 있는 새로운 지식을 추가함- 내면화(Internalization) : 만들어진 책, 교본을 보고 다른 직원의 암묵적 지식을 습득함
>> 이걸 나선형 형태로 회전하면서 생성,발전,전환되는 지식의 발전을 기반으로 한 기업의 경영을 지식경영이라 함.
<데이터와 정보의 관계 - DIKW 피라미드>
- data : 객관적인 사실. 가공하기 전의 순수한 수치나 기호
- Information : 패턴을 인식하고 의미를 부여
- Knowledge : 상호연결된 정보 패턴을 이해하여 이를 토대로 예측한 결과물
- Wisdom : 이해를 바탕으로 도출되는 아이디어
<데이터 사이언티스트의 역량>
- Hard Skill : 빅데이터에 대한 이론적 지식(관련 기법에 대한 이해와 방법론 습득), 분석 기술에 대한 숙련(최적의 분석 설계 및 노하우 축적)
- Soft Skill : 통찰력있는 분석(창의적 사고,호기심, 논리적 비판), 설득력 있는 전달(스토리텔링, Visualization), 다분야 간 협력(커뮤니케이션)
<빅데이터 분석과 전략 인사이트>
- 빅데이터의 과제의 주요 걸림돌은 비용이 아닌 분석적 방법에 대한 이해부족이다.
- 분석을 다방면에 많이 사용하는 것이 경쟁 우위를 가져다 주는 첫 번째 요소는 절대 아니고
단순히 분석을 많이 하는 것이 곧바로 경쟁우위를 가져다 주지 않는다.
- 전략적 인사이트 주는 분석을 통해 복잡한 사업 모델을 단순화하는 것이 적합한 전략이다.
- 빅데이터 분석에서 가치 창출은 데이터의 크기에 의해 좌우된다.
데이터의 크기가 이슈가 아니라 비즈니스 핵심에 대해 보다 객관적이고 종합적인 통찰을 줄 수 있는 데이터를 찾는 것이 중요하다.
- 성과가 우수한 기업들도 가치 분석적 통찰력을 가지고 있다고 대답한 비율이 매우 낮다는 사실이고, 기업의 핵심 가치와 관련해 전략적 통찰력을 가져다주는 데이터 분석을 내재화하는 것은 쉬운일이아니다.
<빅데이터의 가치산정이 어려운 이유>
- 데이터의 활용 방식
> 데이터의 재사용, 재조합 등이 일반화되면서 특정 데이터를 언제 누가 어디서 사용했는지 알 수 없다.
> 재사용 사례 : 검색결과를 저장 후 재사용한다.
> 다목적용사례:전기자동차의 배터리 충전시간, 주유소최적위치 등 , CCTV 절도범 구매정보 등
> 재조합 사례 : 휴대전화 전자파와 뇌종양 관계
- 데이터가 기존에 없던 가치 창출을 한다.
- 분석 기술의 발달이 데이터 가치에 영향을 준다.
<데이터 처리 프로세스 ETL, Extraction, Transformation, Load>
- 데이터 이동과 변환 절차와 관련된 업계표준용어이다.
- 데이터 웨어하우스(DW), 운영 데이터 스토어(ODS), 데이터마트(DM)에 대한 데이터 적재 작업의 핵심 구성요소이다.
- 데이터 통합(Data Integration), 데이터 이동(Data Migration), 마스터 데이터 관리(MDM, Master Data Management)에 걸쳐 폭넓게 활용된다.
- 데이터 이동과 변환을 주목적으로 하며 3가지 기능으로 구성된다.
> Extraction(추출) : 데이터 원천 들로부터 데이터 획득
> Transformation(변형) : 데이터 클렌징, 형식변환,표준화,통합 또는 비즈니스 룰 적용 등
> Loading(적재) : 변형 처리가 완료된 데이터를 목표 시스템에 적재
<빅데이터 활용 테크닉>
- 연관규칙학습 : 커피를 구매하는 사람이 탄산음료를 더 많이 사는가?' 라는 문제에 답하고자 할때. 상관관계 찾아내는 것.
- 유형분석 : 사용자가 어떤 특성을 가진 집단에 속하는가? 와 같은 문제에 답하고자 할때. 그룹을 나눌때 사용할 수 있음.
- 유전알고리즘 : 최대의 시청률을 얻으려면 어떤 프로그램을 어떤 시간대에 방송해야하는가?에 대한 답을 얻고자할때 최적화의 메커니즘을 찾아가는 방법.
- 기계학습(머신러닝):시청자가 현재 보유한 영화 중 어떤 것을 가장 보고 싶어할까?와 같은 문제. 예측하는 일에 초점
- 회귀분석 : 구매자의 나이가 구매 차량의 어떤 영향을 미치는가? 독립변수에 따른 종속변수가 어떻게 변화하는지를 보면 두 변수의 관계를 파악한다.
- 감정분석 : 새로운 환불 정책에 대한 고객의 평가는 어떤가?를 알고 싶을때. 의견을 바탕으로 고객의 원하는 것을 찾아낼때
- 소셜네트워크분석 : 사회관계망분석. 특정인과 다른 사람이 몇촌 정도의 관계인가? 파악할때. 오피니언리더를 찾아낼 수 있음
<빅데이터의 위기요인과 통제방안>
- 사생활 침해: 동의제를 책임제로 바꾸는 방안이 대안
- 책임 원칙의 훼손 : 기존 책임 원칙을 좀 더 보강.
- 데이터 오용 : 알고리즘 접근권에 대한 보장. 객관적인 인증방안 도입. 알고리즈미스트
<빅데이터가 만들어 내는 본질적인 변화>
- 사전 처리 > 사후처리
- 표본조사 > 전수조사
- 질 > 양
- 인과관계 > 상관관계
<데이터 3법 주요 개정 내용>
- 개인정보보호법 / 정보통신망법 / 신용정보법 등 3가지 법률 통칭
- 마이데이터 산업 : 금융분야 마이데이터 사업을 하려면 금융 위원회로부터 허가를 얻은 후 개인의 동의 하에 타 기업에 저장된 개인정보 활용 가능. 금융권에서 많이 쓰는중
<데이터 비식별화>
- 가명처리 : 홍길동 35세 > 임꺽정 30대
- 총계처리 또는 평균값 대체 : 물리학과 학생 키 600cm / 평균 155cm
- 데이터값(가치)삭제 : 홍길동 35세 서울 거주 한국대 졸업 > 35세 서울거주
- 범주화 : 홍길동 35세 > 홍씨, 30~40세
- 데이터마스킹 : 홍길동 > 홍 **
<빅데이터 기능>
- 산업혁명의 석탄, 철에 비유된다.
- 원유에 비유된다
- 렌즈에 비유된다
- 플랫폼에 비유된다.
'ADsP' 카테고리의 다른 글
| ADsP 3과목 데이터분석 정리 (1) (0) | 2023.08.18 |
|---|---|
| ADsP 2과목 데이터 분석 기획 정리 (0) | 2023.08.18 |
| ADsP 31회 기출문제 정리 (0) | 2023.08.16 |
| ADsP 34회 기출문제 정리 (0) | 2023.08.15 |
| ADsP 32회 기출문제 (0) | 2023.08.15 |


