Keras라는 라이브러리를 사용해 신경망 모델을 실제로 구현해보기.
1. 데이터를 준비하고
2. 신경망 모델을 구축하고
3. 모델에 데이터를 전달해서 학습시키고
4. 모델의 분류 및 정확도를 평가함.
* 전결합층 : 모든 뉴런이 이전 층의 뉴런에 결합하는 층
* 심층 신경망 : 어느정도 깊이 있는 신경망
* 입력층 : 입력을 맡은 층
* 출력층 : 출력하는 층
* 은닉층 : 입력층과 출력층 사이의 층
* 노드 : 세로로 늘어선 벡터 하나하나의 요소
* 노드 수 : 노드의 차원 수
* 원- 핫 벡터 one-hot encoding/vector : 단 하나의 값만 True(Hot)이고 나머지는 모두 False(Cold)인 인코딩
<Keras>
- Keras는 TensorFlow의 래퍼(wrapper, 다른 시스템에 해당 시스템을 내포하여 보다 사용하기 쉽게 만드는 것)라이브러리.
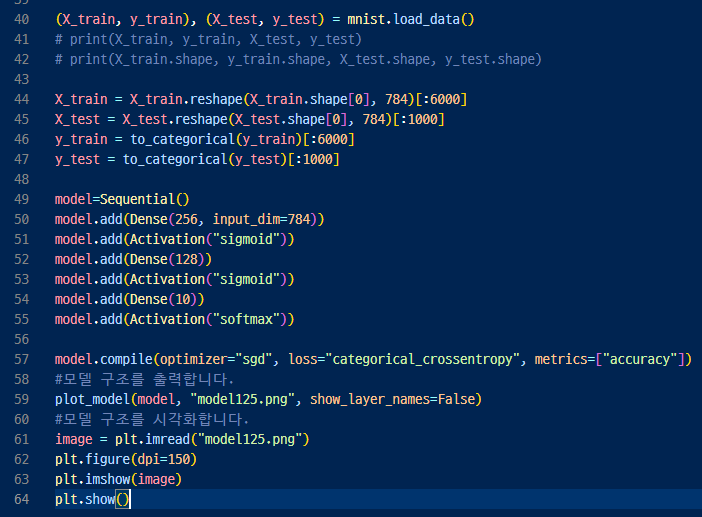
49행. Keras로 모델을 관리하는 인스턴스를 만들고
50/52/54 행. add() 메서드를 사용하여 모델을 한층씩 정의하고
51/53/55 행. 시그모이드 함수 sigmoid나 ReLU함수 relu 등을 설정해 전 결합층의 출력은 활성화 함수를 적용한다.
57행. 컴파일 메서드 compile()을 이용하여 어떠한 학습을 실시할지 설정하면 모델 생성이 종료된다.
▶ Dense https://keras.io/api/layers/core_layers/dense
▶ Sequential https://keras.io/ko/getting-started/sequential-model-guide/
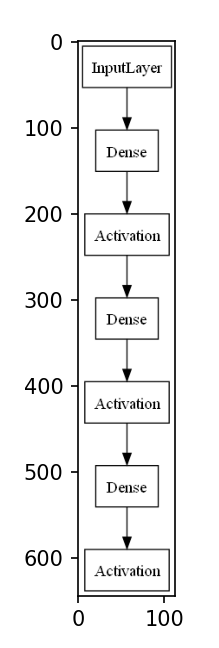
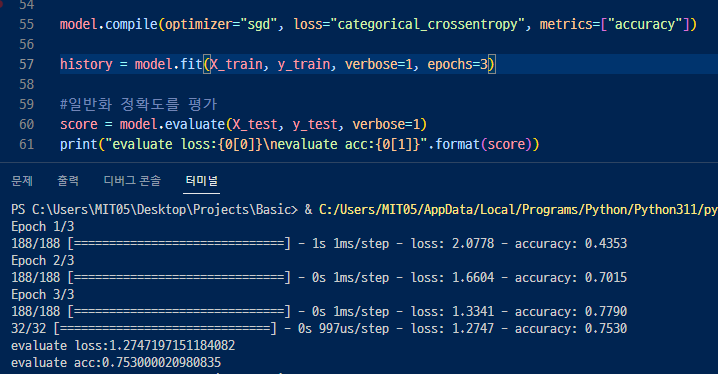
▶ 모델에 훈련 데이터를 전달하여 학습시킨 후 정확도 accuracy가 점차적으로 오르는지 확인하기
57행. verbose = 1로 하면 학습 등의 진척을 출력하고 0으로 하면 진척을 출력하지 않음.
epochs에는 동일한 데이터 셋으로 몇 번 반복 학습할지 지정함.
fit() 메서드는 학습용 데이터를 순서대로 모델에 입력. 출력 및 지도 데이터 간의 차이가 작아지도록
뉴런의 가중치를 조금씩 갱신함. 이에 따라 예측 정확도가 향상됨

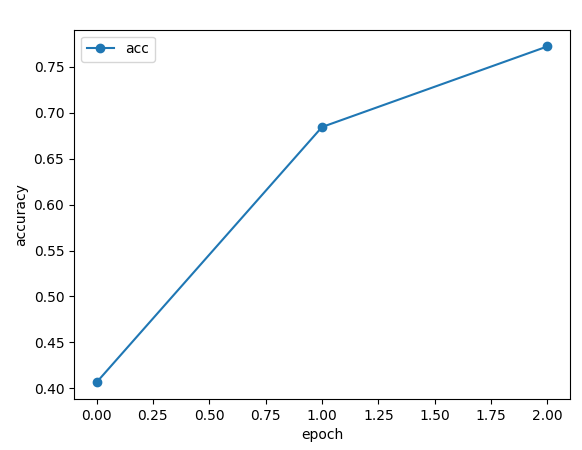
▶ 정확도가 0.40 > 0.68 > 0.77 로 점점 오르는것을 볼 수 있음.
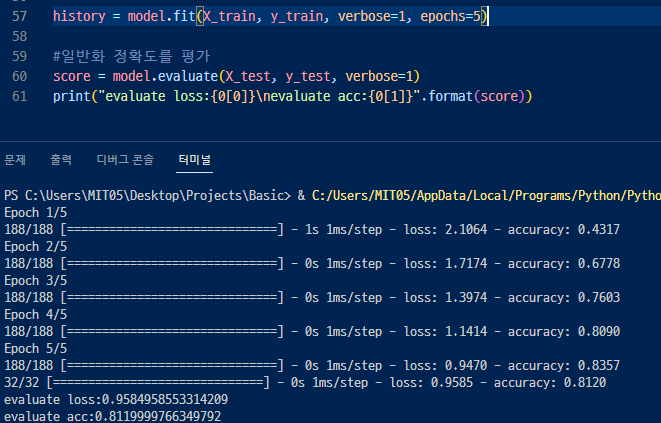
epoch 수를 더 늘리면 더 많이 학습하여 점점 올라감 (내려갈수도있고 비슷할 수도 있음)
<모델 평가>
학습에 사용되지 않았던 테스트 데이터를 사용해서 모델로 분류하고 모델의 평가를 실시
evaluate( )는 손실 함수의 값과 정확도를 얻을 수 있음.
loss 는 예측값과 실제값이 차이나는 정도. 작을 수록 좋음.
<모델에 의한 분류>
model의 predict () 메서드로 예측치를 얻을 수 있음.
argmax(https://numpy.org/doc/stable/reference/generated/numpy.argmax.html#numpy-argmax) 함수로
가장 큰 값을 반환하는 뉴런의 위치를 취득하고 있음.
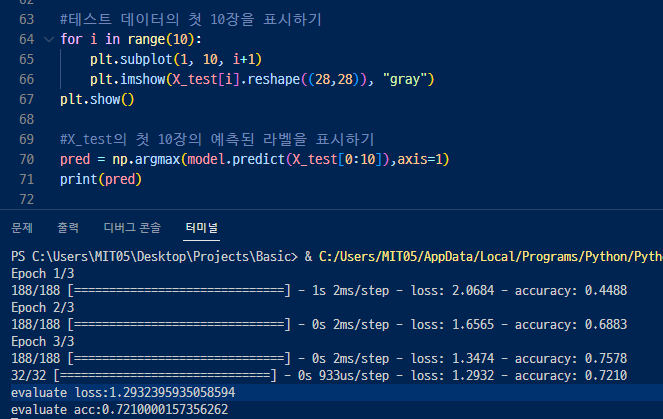
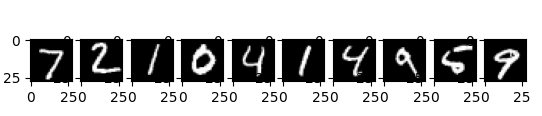

▲ 위 글씨체를 아래의 데이터로 판별한 것. 정확도 0.72 밖에 안되어서 잘 맞지 않음.
<총정리>
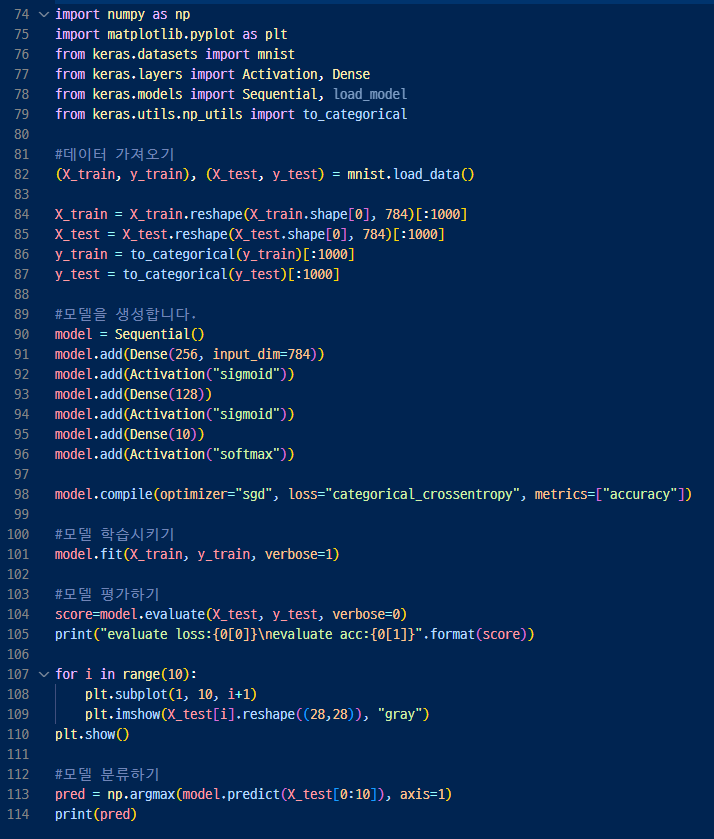
90행. 모델을 관리하는 인스턴스를 만들고
91~96행.한층씩 은닉층(hidden layer)도 추가하고
101행, model.fit(학습데이터, 지도데이터)로 학습시킨다.
113행. modelpredict를 통해 예측치를 얻을 수 있다.
▷ np.argmax()는 배열의 최대 요소를 인덱스로 반환하는 함수로
predict를 통해 0~9까지의 숫자 배열이 출력되고
argmax()로 출력된 배열의 최대 요소를 돌려줘서 예측된 숫자가 어디에 가까운지 보기 쉽게 할 수 있다.

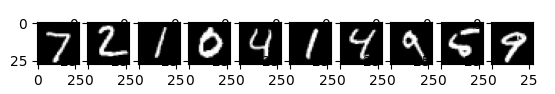
다른데이터 / 다른모델적용하기 / 학습을 더 많이하거나 / 이상치를 제거하거나 / 은닉층을 더 많이 나누거나
등등의 정확도를 높이기 위한 다양한 작업들을 할 수 있다. > 하이퍼파라미터를 더 공부하면 알 수 있음.(다음)
* history = model.fit(X_train, y_train, batch_size=500, epochs=5, verbose=1, validation_data=(X_test, y_test))
> 일때는 그래프가 나오지만
history = model.fit(X_train, y_train, verbose=1, epochs=5)
> 이때는 왜 안나올까.....ㅎ.
▼ 그래프 그리면
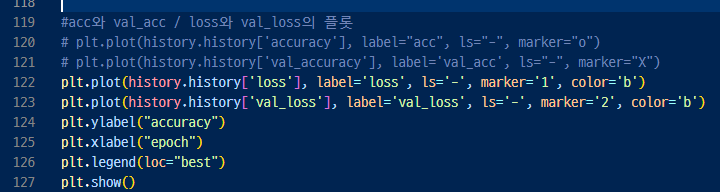
일단
history = model.fit(X_train, y_train, batch_size=500, epochs=5, verbose=1, validation_data=(X_test, y_test))
여기에서 epochs를 빼보면, 1번밖에 안해서
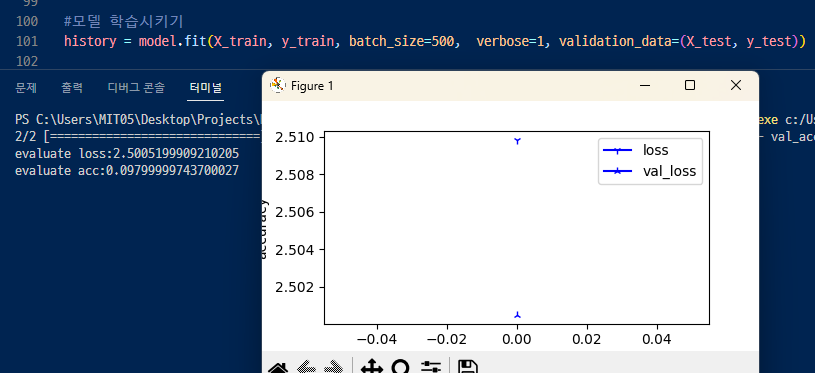
이렇게 밖에 안나온다
그래서 batch_size=500 를 빼봤는데
history = model.fit(X_train, y_train, epochs=5, verbose=1, validation_data=(X_test, y_test))
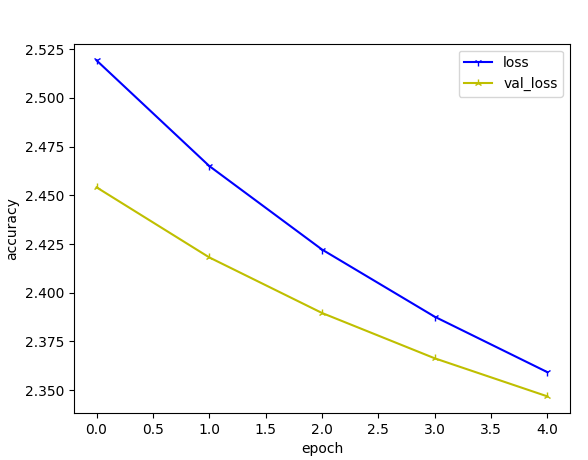
이래도 나온다.
validation_data=(X_test, y_test)를 빼보니까
history = model.fit(X_train, y_train, batch_size=500, epochs=5, verbose=1)

에러가 난다..!
validation_data가 있어야 val_loss랑 val_acc를 불러올 수 있는 것 같다.
validation_data에 대해서는 이렇게https://velog.io/@dltjrdud37/TIL-20210223
> 검증데이터(테스트데이터)를 넣어줘야지 val_loss, val_acc를 불러올 수 있다.
검증데이터(validation_data)를 안넣어주게되면 그냥 loss랑 acc만 불러올 수 있다.
'머신러닝 > 딥러닝' 카테고리의 다른 글
| 딥러닝 CNN + 개념정리 (0) | 2023.07.31 |
|---|---|
| 딥러닝 하이퍼파라미터(학습률,미니배치,반복학습) (0) | 2023.07.25 |
| 딥러닝 튜닝, 드롭아웃, 활성화함수, 손실함수, (0) | 2023.07.25 |
| 딥러닝 튜닝, 하이퍼파라미터와 네트워크 구조 (0) | 2023.07.25 |
| 딥러닝의 기초 (0) | 2023.07.24 |



