데이터를 다루다보면 열의 데이터가 반복될때가 있음.
이런 반복되는 데이터는 따로 관리하는 것이 좋은데,
왜 그런걸까? 따로 관리하려면 어떻게 해야할까?
1. 빌보드 차트 데이터를 불러와서 year, artist, track, time, date.entered(반복될수도있는 열) 을 pivot 처리함
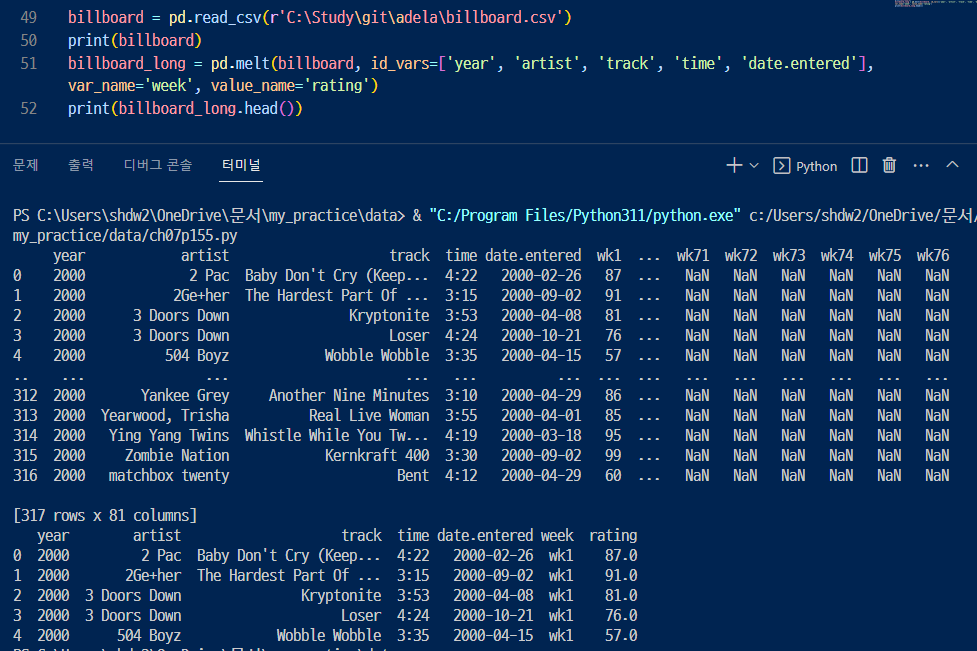
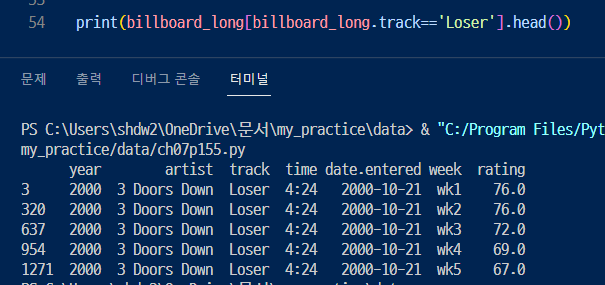
2. 그래서 노래 제목을 살펴보면,,,, 중복 데이터가 꽤나 많음. > 그치 노래차트니까
예를 들어 가수는 고유한 값이기 때문에 따로 관리하는 것이 데이터 일관성을 유지하는데 도움됨
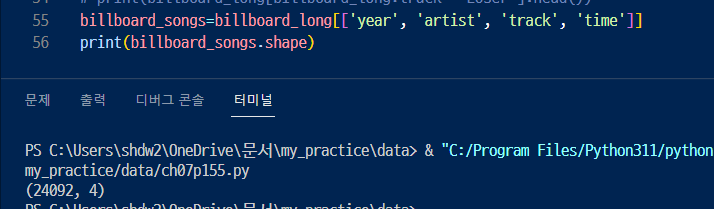
3. 그래서 중복 데이터를 가지고 있는 열을 묶어서 새로운 데이터프레임에 저장하고
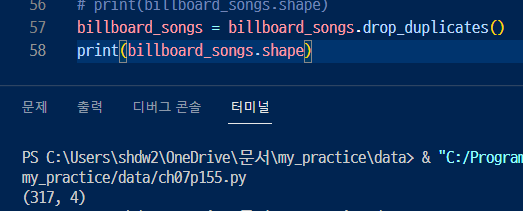
4. drop_duplicates 메서드로 중복 데이터를 제거 ( 와 어마어마하게 제거가 되었구만)
5. 그리고 id 라는 새로운 열도 추가해봄.
> id 가 있으면 데이터를 쉽게 조회하거나 구분할 수 있으니까,

6. 그리고 merge 메서드를 사용해서 노래 정보와 주간 순위 데이터를 합쳐봄

그렇게 중복 데이터는 합쳐서 깔끔하게 처리할 수 있다,,
'데이터분석 > Pandas&Numpy' 카테고리의 다른 글
| pandas 잘못 입력한 데이터 처리하기 (0) | 2023.07.03 |
|---|---|
| pandas 자료형 astype()를 사용해 자유자재로 변환하기 (0) | 2023.07.03 |
| pandas 여러개 분리된 열을 깔끔하게 데이터 정리 하는 방법 (0) | 2023.06.29 |
| pandas 열 이름 관리 - 여러의미를 가지고 있는 하나의 열 (0) | 2023.06.29 |
| pandas 깔끔한 데이터 만들기 - 열과 피벗 (0) | 2023.06.28 |



