- 분석하기 좋은 데이터 : 데이터 집합을 분석하기 좋은 상태로 만들어놓은것
> 실제로 데이터 분석 작업이 70% 이상될정도로 아주 중요함.
>> 1. 데이터 분석 목적에 맞는 데이터를 모아 새로운 표로 만들어야 함.
>> 2. 측정한 값은 행(row)을 구성해야 함.
>> 3. 변수는 열(column)로 구성해야함
>>>>>>> 이것은 바로 깔끔한 데이터(Tidy data)라 부름
* 데이터 연결하기
- concat (Concatenation)
- concat 메서드에 데이터프레임을 리스트에 담아 전달
> 위에서 아래방향으로 연결됨.
> 해당 데이터들은 열의 이름이 모두 A,B,C,D로 같기 때문에 열이 그대로 유지됨.

- 연결한 데이터프레임에서 행 데이터 추출 : iloc, loc 등 무난 하게 가능
> 기존 데이터프레임에 있던 인덱스가 그대로 유지됨

- 데이터프레임 + 시리즈 : concat 로 연결해보기

▲ 새로운 '열'로 추가됨. 채워지지 않은 부분들은 NaN이라는 값으로 나오는데, 이것이 바로 누락값
▲ 행이 1개라도 반드시 데이터프레임에 담아 연결해야함 (행추가하려면!!!!!!!!!)
> 시리즈는 행이 1개인 데이터 프레임이지만 열값이 없기 때문에 추가해줘야,,

- concat은 한번에 2개 이상의 데이터 프레임을 연결 할 수 있음.
▼ 연결할 데이터프레임이 1개라면 _append 메서드를 사용해도 GOOD

▼ 위처럼 columns 값을 줘도 되지만 딕셔너리 구조로 {열이름: 값} 을 줘도 됨!!!!!!
- ignore_index 로 하면 인덱스 값을 0부터 깔끔하게 쫙 다시 지정함.

- ignore_index = True 의 또 다른 예

----------- 위에서는 요랬다구여 (행 인덱스 엉망진창)

- concat 의 axis 인자를 1로 지정 : 열 방향으로 데이터 연결
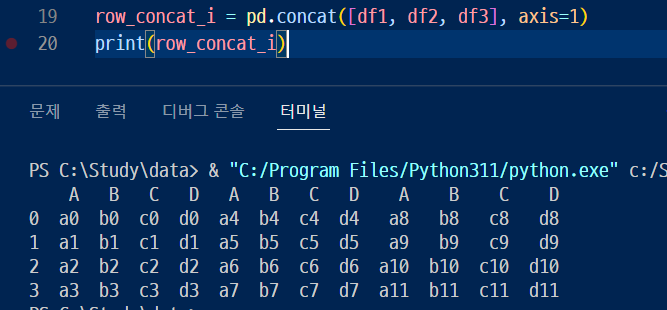
- 그럼 이렇게 열 이름으로 추출 할 수 있음~~~~

- 데이터프레임 [ 새로운 열이름 ] = [데이터값 리스트로]
>> 그럼 아래와 같이 열이 하나 추가된다.

그리고 열 이름을 유지하면 중복이 될 수도 있으니까
- ignore_index = True 지정하면 열 이름을 다시 행의 인덱스처럼 하나로 지정해줌

< 공통 열과 공통 인덱스만 연결하기 >
- 기존에 있는 df1, df2, df3 열 이름을 다시 지정함. (공통되게)

- 새롭게 열 이름을 부여한 후 합쳐보기.
> 그러니까 없는 열 이름의 데이터는 누락값(NaN)으로 처리됨

- 누락값 없이 하려면?
>>> 공통 열만 골라서 연결하면 되지 >>> 그건 바로 join 인자를 inner로 하면됨
▼ 그렇지만 여기서는 df1, df2, df3 의 공통된 값이 없으니까 아무것도 없는 empty 가 나옴


- 그래서 공통된 열이 있는 df1 , df3 을 합쳤고 그럼 공통된 열인 A와 C만 나옴

- 데이터 프레임을 행 방향으로 연결해보기
> 1. df1 , df2 , df3 의 인덱스를 다시 지정해보기
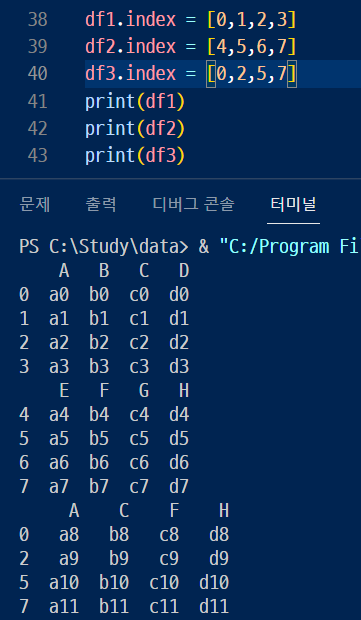
> 그리고 axis = 1 인자값을 주고 행 방향으로 연결.
> 그러니까 NaN(누락값) 엄청 생김..!

- 그래서 df1, df3의 공통 행만 골라서 연결해보기
> 그러니까 공통 행인 0과 2만 출력됨

< 외부조인과 내부조인>
- 내부조인 : 2개 이상의 데이터프레임에서 조건에 맞는 행 연결
- 외부조인 : 왼쪽외부조인(Left Outer Join)과 오른쪽 외부조인(Right Outer Join), 완전 외부 조인(Full Outer Join)이 있음
> 왼쪽(오른쪽) 외부 조인 : 왼쪽(오른쪽) 데이터프레임을 모두 포함해 연결
> 완전 외부조인 : 왼쪽과 오른쪽 데이터프레임을 모두 포함해 연결
'데이터분석 > Pandas&Numpy' 카테고리의 다른 글
| series에서 name (0) | 2023.06.27 |
|---|---|
| pandas merge이용해서 연결하기 (0) | 2023.06.25 |
| pandas / seaborn 그래프 스타일 설정하기 (0) | 2023.06.24 |
| pandas/ matplotlib으로 그래프 그리기 (0) | 2023.06.24 |
| pandas / FaceGrid 클래스로 그룹별 그래프 그리 (0) | 2023.06.24 |



