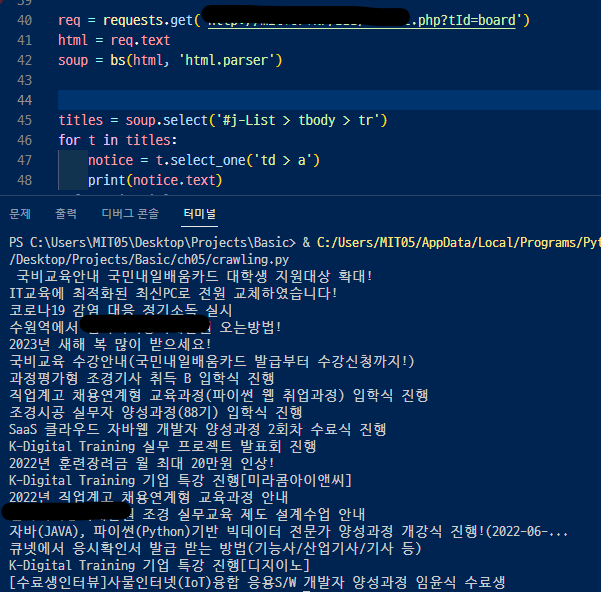
웹크롤링 - 네이버뉴스제목 / 홈페이지 공지사항 제목 가져오기
<웹의 통신 이해> - 좀더자세히공부할필요가있음
- 웹에서 어떤 데이터(또는 정보)를 얻기 위한 방법
- API : https://dev-adela.tistory.com/44
- 한번 연결하고 닫음. 계속 연결이 되어있는 것이 아니라 요청했을때마다 열고 필요한것만 보내주고 연결 끊음.
<웹크롤링>
- 짧은 시간 동안 지속적인접속을 하면 서버에 부하를 줄 수 있음.
> 거부를 당할 수 있음
- robots.txt 를 통해 서버에 만들어 두고 있는데. 크롤러에게 허용가능한 부분들 보여줌
- User-agent : *
Disallow: /
Allow : /$ ( 그이하의 디렉토리는 다 ㄱㅊㄱㅊ)
> 구글같은 경우에는 이렇게 https://developers.google.com/search/docs/crawling-indexing/robots/robots_txt?hl=ko
> 자세한 상세 내용을 알 수 있음.
- 수집 절차
: 수집할 데이터를 정의 > HTML 코드 내려받기 > 원하는 태그 접근 > 원하는 데이터 추출 > 저장
<구글 첫 페이지의 소스를 가져오기>
▼ (파이썬 라이브러리) urllib를 사용하면 벼로의 설치 없이 간편하게 HTTP request를 가져올 수 있음.

▶ 바이너리 코드로 읽어짐
requests.get(get방식으로 요청, 키값이 보이는거
requests.port( HTTP POST 방식으로 요청, 키값이 안보이는거. )
response.status_code(요청에 대한 답장을 코드로 보내줌- 상태코드를 통해서 알 수 있음. 200이 정상, 403금지 404찾을수없음)
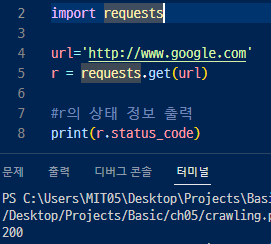
▼ requests를 사용하여 상태 정보 출력해봄. 200이니까 정상, 성공이라는 얘기 .
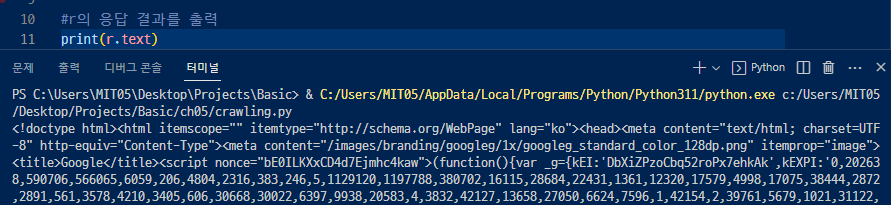
▼ 텍스트 형태로 결과(내용)를 불러옴. 앞에 'b'가 없는걸 보면 바이너리 코드가 아닌 텍스트인걸 확인할 수 있음.
▼구글 로고를 가져오기 위해서 구글 로고의 이미지 주소를 불러와 객체 형태로 메모리에 저장된 것을 확인할 수 있음.
> 쥬피터나 코랩으로 하면 바로 이미지로 볼 수 있음.

find_all, fina, select(선택자 / 선택자를 사용한 데이터 선택)

일반적으로 이렇게 했을 때 이런 에러가 뜰 수 있다.
requests.exceptions.ConnectionError: ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response'))
> 브라우저로 접속하지 않아서 뜨는 에러. 브라우저로 접속하지 않는다고? 금지한다! 이런 느낌
https://docs.python-requests.org/en/latest/user/quickstart/
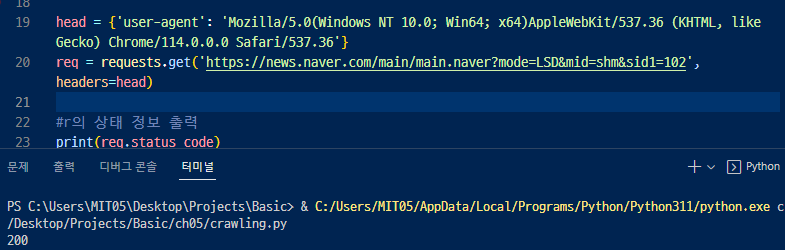
▲ user-agent 를 검색해서 공부해보자.
https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers/User-Agent
▲ 브라우저로 접속하는 것 처럼 적어주는 것. header 파라미터에 인자로 전달해주면 됨. 브라우저를 쓰지않지만 브라우저를 쓰는 것 처럼 하는것
그래서 200이라고 접속 성공이라고 뜸. > 만약 안나오면 접속방식(head)를 바꿔주면됨.

BeautifulSoup을 통해 파싱하고나면 출력화면이 html 처럼 깔끔하게 정리되어서 나온다
27행. html 을 파싱하는거니까 html 이라고 적어
▶ 파싱 내용 여기도 있음 : https://dev-adela.tistory.com/50
▼ 정치,경제,사회면도 가져오기 위해서 주소 뒤에 바뀌는값을 딕셔너리로 만들어주고 for문을 써서 불러온다
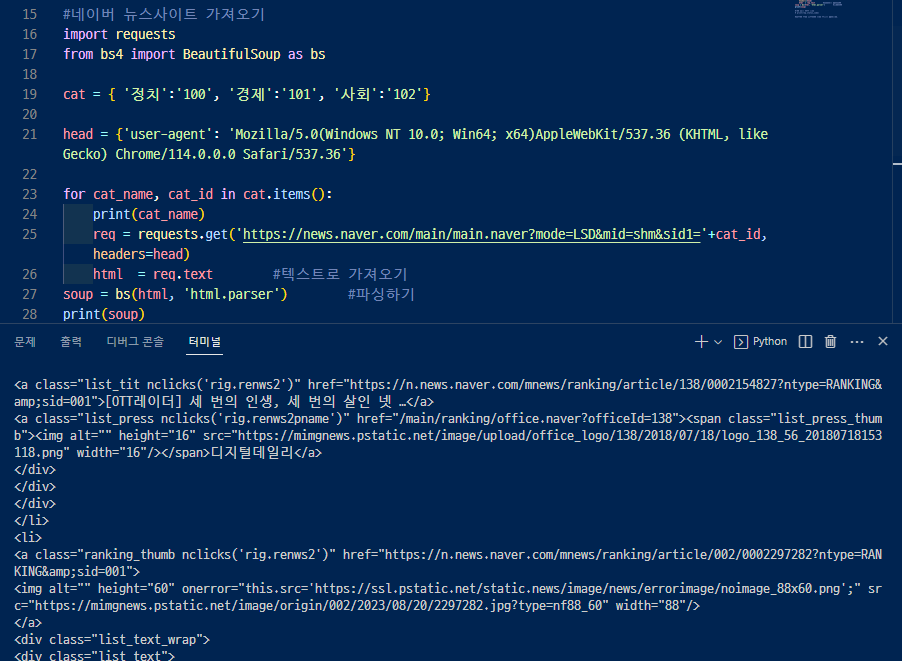
제목과 연결 링크만 가져오기 위해 select와 select_one 메서드를 사용


▶F12 (Ctrl+U, 오른쪽클릭+페이지소스보기)를 해서 가져오기 위한 정보가 어느 위치에 있는지 확인.
>> 클릭한 부분에서 오른쪽 클릭 + Copy 를 하면 위치를 복사할수있음. 여기서는 copy selector 를 한 것

▶select를 사용해서 그 위치까지 가서 select_one으로 앵커태그에 있는 제목과 주소를 불러올 수 있음.
class, href( 속성이름), 거기에 = 해서 나오는 내용들 (속성값)
<▼위에꺼 한꺼번에 쓴거>

<홈페이지 공지사항 불러오기>