데이터분석
정규식표현 문법, 특수 문자, 메서드 정리
ADELA_J
2023. 7. 4. 17:14
<정규식 표현 - 문법>
| 문법 | 실습 코드 | 설명 |
| . | .a | 문자(a) 앞에 문자 1개가 있는 패턴을 찾기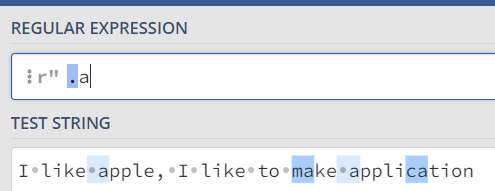 |
| ^ | ^I like | 문자열의 처음부터 일치하는 패턴을 찾기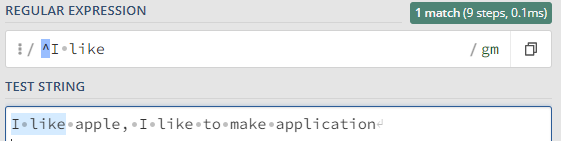 |
| $ | on$ | 문자열의 끝 부분부터 일치하는 패턴 찾기 |
| * | n\d* | n 이후 숫자(\d)가 0개 이상인 패턴을 찾기 |
| + | n\d+ | n 이후 숫자(\d)가 1개 이상인 패턴 찾기 |
| ? | apple? | ?의 앞의 문자(e)가 있거나 없는 패턴 찾기 |
| {m} | n\d{2} | n 이후 숫자(\d)가 2개({2})인 패턴 찾기 |
| {m, n} | n\d{2,4} | n 이후 숫자(\d)가 2개 ({2}) 이상, 4개 ({4}) 이하인 패턴 찾기 |
| \ | \*, \?, \+ | *, ?, +와 같은 특수 문자를 검색할 때 이스케이프 문자 사용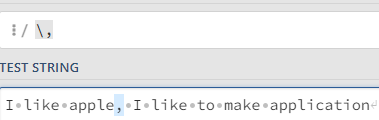 |
| [ ] | [cfh]all | c,f,h 중 1개를 포함하고 나머지 문자열이 all인 패턴을 찾기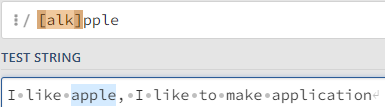 |
| | | apple | application | apple 이나 application 중 하나만 있는 패턴을 찾기 (or 연산)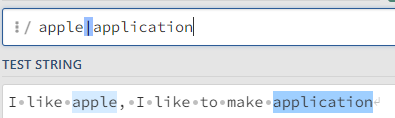 |
| ( ) | (\d+) - (\d+) - (\d+) | ()에 지정된 패턴을 찾을 때 사용 |
<정규식 특수 문자>
| 특수 문자 | 설명 |
| \d | 숫자 1개를 의미 ([0-9]와 동일). |
| \D | 숫자 이외의 문자 1개를 의미합니다 ([^0-9]와 동일) |
| \s | 공백이나 탭 1개를 의미 |
| \S | 공백 문자 이외의 문자 1개를 의미 |
| \w | 알파벳 1개를 의미 |
| \W | 알파벳 이외의 문자 1개를 의미 (한글 중국어 등등) |
<정규식 표현 - 메서드>
test = 'I like apple, I like to make application'
로 실습해봄
| 함수 | 실습코드 | 설명 |
| search | m = re.search('[0-9]{4}', test) print(m.group()) >> None 이라 안나오는데..ㅎ |
첫 번째로 찾은 패턴의 양 끝 인덱스를 반환 |
| match | m = re.match('[0-9]{4}', test) print(m) >> 요것도 none.. |
문자열의 처음부터 검색하여 찾아낸 패턴의 양 끝 인덱스 반 |
| fullmatch | m = re.fullmatch('\d+\s\d+\s\d+\s\d+', test) print(bool(m)) >>False가 나옵니다 숫자가없으니 |
전체 문자열이 일치하는지 검사 |
| split | m = re.split('\s', test) print(m) >> ['I', 'like', 'apple,', 'I', 'like', 'to', 'make', 'application'] |
지정된 패턴으로 잘라낸 문자열을 리스트로 반환 |
| findall | m =re.findall('[0-9]{4}', test) print(m) >> [ ] |
지정된 패턴을 찾아 리스트로 반환 |
| fin | m = re.finditer('[0-9]{4}', test) for match in m: |
findall 메서드와 기능이 동일하지만 iterator를 반환 |
| sub | print(re.sub('\s', '-', test)) '010-1234-5678-090' |
첫번째 인자로 전달한 값(패턴)을 두 번째 인자로 전달한 값(asyspub)으로 교체 |
▲ 위 함수 중 split 은 구분 기호로 자를 수도 있다.


순서/쉼표 구분없이 그냥 리스트에 적어주면 리스트 안에 있는 기호에 맞춰 문자가 잘라져 리스트로 반환된다.