Seaborn 그래프 그리기 기초
- sns.load_dataset(불러올 데이터 셋 이름)
> seaborn에서 제공하는 데이터셋 불러오기
- sns.get_dataset_name() ( 제공해주는 데이터셋을 보여줌)
<seaborn에 있는 dataset중 'tips', 아래 데이터를 기반으로 진행해보쟈>

▶ Non-Null Count 보면 누락값이 아무것도 없다는것
(244개의 행에서 244 non-null이니까)
- .describe() 로 기초 통계를 출력할 수 있음.
▷ float와 int만 계산되어서 나온거

▲▲▲▲▲ 먼저 데이터를 받으면 head, info, describe를 통해 데이터를 확인해야함.
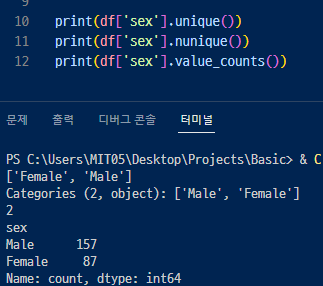
- unique()를 통해서 값이 어떻게 나누어지는지 확인할 수 있고
- nunique() 를 통해서 몇 개의 그룹으로 나누었는지 확인할 수 있고
- value_counts() 를 통해서 나누어진 그룹의 각각 갯수(행 갯수)를 확인할 수 있음.
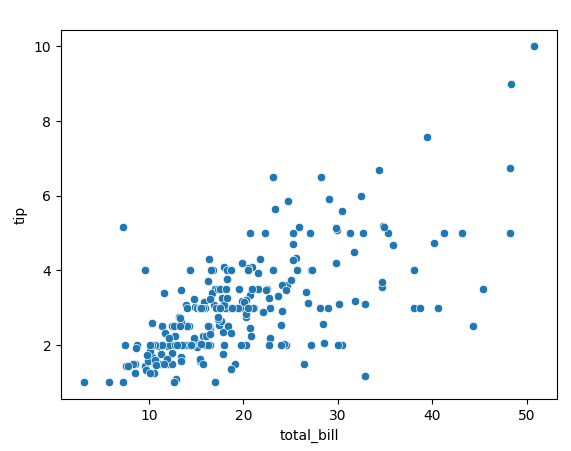
<seaborn 산점도 그래프 scatterplot> - 관련 포스팅 https://dev-adela.tistory.com/97
- x와 y축 변수의 상관관게를 알아볼 때
- 오른쪽 위로 상승하면 양의 상관관계 / 오른쪽 아래로 하강하면 음의 상관관계
- sns.scatterplot (x, y ,hue=그룹핑할 변수(색상), size=, style=점모양, data=데이터프레임)
이렇게 data = df로 정해주고 해당 열 이름만 x,y로 정해줘도되고

이렇게 하나하나 정확히 적어줘도되고 (data가 다를경우 쓰면 더 좋지않을까)


<사실 이렇게 양이 적을때는 바 그래프가 최고>


꺾은선은 이렇게 그리기

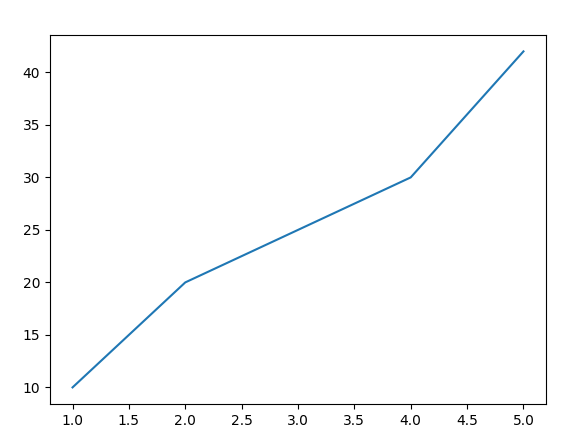
위에 있었던 데이터에서 size와 tip를 꺾은선 그래프 그리기


>> 산점도를 통해서 변화량을 알기 어려울때 꺾은선 그래프를 사용해서 하기도 함.
- x축 값에 해당하는 y축의 값이 여러 개 존재하기 때문에 값의 분포를 나타내는 부분이 함께 표시됨.
- size가 2인 경우 대부분 tip의 값이 표시된 직선 값에 수렴하는 반면,
size가 5인 경우 값의 편차가 큰 것을 알 수 있다.
<막대그래프>
pointplot은 막대그래프에서 막대를 제외하고 데이터의 평균값을 선으로 잇고
신뢰구간을 함께 표시한 그래프
>> 평균값을 표시하지만 범주형 변수(카테고리컬 데이터) 의 값의 분포를 표시하는 것이 좀 더 맞는 그래
https://seaborn.pydata.org/generated/seaborn.pointplot.html?highlight=pointplot


- 값의 대한 숫자 메서드 .value_counts()
